This post will list a non-exhaustive taxonomy of data store types, and outline how they can be used to model different problem domains.
Data Modelling
In database design, modelling can be defined as the process of mapping the entities and events from a particular domain, into a representational format that can be stored into a database. The goal is to be able to answer relevant questions with data once it’s stored. Suitably, when model our domain, we must think of data in the way that it will be processed, as opposed to presented; and depending on what our domain is, some data store types may be more practical in helping us answer certain types of questions better than other. Understanding the strengths and weaknesses of each data store type can greatly ease the decision of which would be more suitable for a particular task we have in hand.
It is not uncommon to have a setup with multiple data store types, each excelling in their own particular field. For example, while in-memory key-value stores are often used to handle authentication data, relational data stores are often used to keep banking transactions. Also, while Row Based Relational data stores tend to handle transactional operations better, Column Based data stores excel at analytical data processing operations like generating reports. Just as data store types are geared for certain types of tasks, our problem domains can have a natural inclination towards one datastore type over others. We will see how this can affect our decisions when picking a data store, and what types of problems each store was designed to handle.
Data Store Types & Use Cases
There are several different types of data stores in our field today. Some of these, like graphs and relational stores, are older, and more familiar than others. Some are relatively new in popularity, and traction, though not necessarily in their concept. One way to define the taxonomy of data stores is to split them into 5 non-exhaustive groups:
- Relational: MySQL, PostgreSQL
- Key-Value: Redis, Voldemort
- Document: MongoDB
- Column-based: HBase
- Graphs: Neo4j, TitanDB
Addressing the particularities of each of these types is beyond the scope of this post, and my knowledge. Yet, I will attempt to define some of the key aspects that separate them from each other.
Relational Stores: These are the data stores we are most familiar with. They basically store data in tables, with a defined schema, organised by rows, where each row represents an individual record. These data stores work really well for relational (think relationships between records) data processing. Most stores, like MySQL, are designed for real-time, transactional data processing, where insert and update operations can happen very quickly.
E-commerce websites are an example of a domain where this is optimum. There are products, related to suppliers, and sales, which in turn relate to orders, and direct relationships are where SQL stores do well.
Products
| id | name | supplier |
|---|---|---|
| 1 | Shampoo | 12 |
| 2 | Toothpaste | 9 |
Suppliers
| id | name |
|---|---|
| 9 | Body Care Industrial Ltd |
| 12 | KPT International Ltd |
Sales
| id | product | order |
|---|---|---|
| 23 | 1 | 123 |
| 23 | 45 | 123 |
| 24 | 432 | 124 |
Orders
| id | status |
|---|---|
| 123 | Delivered |
Each individual row in each table keeps the details of each entity, and they are connected to one another through Foreign Keys, which allow us to ask questions such as “which products were added to order 123, and who supplied them?”, in real-time. Note that other stores, like graphs, can also answer these questions. I’m just highlighting the prime use cases of each store.
Key-Value Stores: Key-Value stores are much simpler compared to the other data stores. They pretty much work like HashMaps or Dictionaries. They hold a set of unique keys, usually strings, that map to a single value, which can be of any time, e.g. string, number, list. Redis, although it’s an in-memory store, is a good example of a key-value store, and Voldemort is another which offers data persistence, if that’s what you need. These stores are suitable for doing things like caching values for uniquely identified resources, that require high volume, high speed access.
For example, Redis is used to store authentication tokens to be shared across servers for authentication, without hitting a database. Generally, any uniquely identifiable resource that needs to be constantly read can benefit from being kept in a key-value store. They provide highly concurrent access, at low latency.
Document Stores: Document stores are, well, document oriented data stores that keep collections of document-objects, with nested structures. More often than not, these documents will be in the form of JSON-objects. MongoDB is an example. MongoDB can store large documents, or JSON-objects, with other nested objects that have a parent-child relationship, with deeply nested hierarchies.
For instance, if we need to model the population, and other census data for each locality, within each state, within each country, this is what the model might look like:
The sample is kept short, for illustration purposes. The nested relationships between the entities makes this problem domain very suitable for a document store like MongoDB. Not only would be it be easy to map the model from real-life to the format it’s stored, but retrieving information in bulk, like the details for population by locality for one or several countries, would also be practical, and fast. So, if we wanted to ask questions like, which localities, in which countries, have a population above 60,000, this would be a good fit for a document store. Note that a Relational store can also store this type of data. The advantage offered by document stores like MongoDB is the flexibility of schema, which makes the addition and removal of fields more practical to perform. To my knowledge, document stores are useful to store independent, or loosely coupled data entities. So if we wanted to perform transactions that span across entities that were connected to one another, then we should consider the implications it might have on our application, and perhaps we might be better off looking at other alternatives. Otherwise, we can always test it, and see if it fits our needs.
Column-Based: as stated earlier, column-based data stores are very practical for analytical data processing, e.g. report generation. Just like relational data stores, column-based data stores use tables. However, due to their nature of keeping data organised in columns, as opposed to rows, performing aggregation operations like summing up sales values is much easier compared to a relational data store. In practice, it is said that column-based stores can replace relational data stores when we reach a point of difficulty in scaling with relational stores, or high volume capacity, say above 50GB. Still, this would only serve us if we were performing analytical operations. Otherwise, there may not be much benefit for the domain being modelled.
Apache HBase is an example of a column based store. It can cater to both analytical and transactional processing; though it is not necessarily strong with relational-analytical or relational-transactional processing. Meaning, if our processing spans across several entities, in different tables, we may want to consider our other options.
Graphs: made popular by websites like Facebook, and LinkedIn, graph data stores have actually been around for quite some time. Graph stores are based on graph theory, and as such are comprised on edges (nodes) and vertices (relationships). In a graph data store, our entities are modelled as nodes, with properties, and the connections between them are represented by relationships, which may be uni or bi-directional, and can have properties as well.
An immediate example of a domain that is naturally inclined to this kind of data store are social networks.
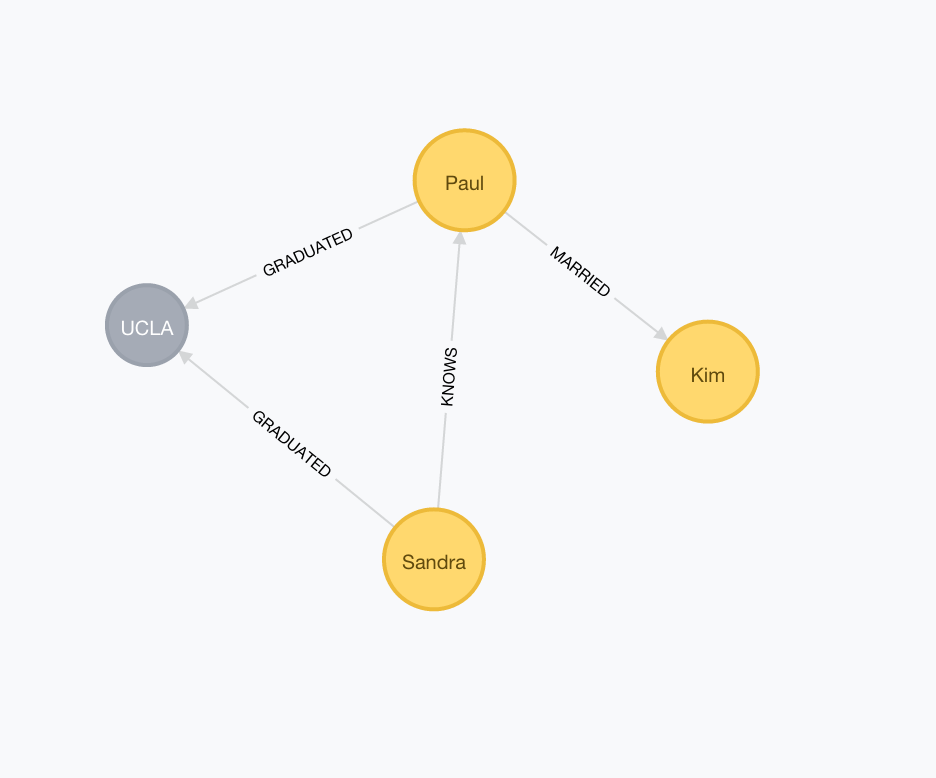
Graphs data stores are very resourceful when we want to make sense out of connected data. We can model different kinds of entities, and their relationships with little effort. And adding new types of entities and relationships is just as easy, as they mostly work without a schema.
The key use of graphs though, is to find “hidden” connections. Looking at our graph, we can see that it can also be modelled in relational-like store. However, when we have a dense graph, with many entities connected to each other, we can start asking some interesting questions. For example, how many people would be have to go through to establish a link between two people? Might Kim “know” Sandra through someone else, other than Paul?
This is called a path traversal, and it is where graphs do much better than other stores. For example, asking which of Sandra’s friends, have friends whose friends went to her school, and are not married can be an overkill for a relational or document data store. A nested table scan of 1-3 levels can be well managed, but paths that cut across different entities, and span several nodes until they reach their destination, while observing conditions are much more practical to handle in graph stores. Graphs are also capable of handling other modelling domains. Data Stores like Neo4j are very fast at path traversals, and they have been applied in several domains, from social graphs to logistics.
Notwithstanding, modelling data in graphs can be a bit tricky, depending on our domain problem. This will addressed in a future post, where I will attempt to prescribe some general guidelines for modelling graphs.
Closing Notes
Just like in any statistical or scientific experiment, a data modelling problem must always begin with questions in mind:
- How will we process our data (e.g. generate sales reports, find proximity between people, retrieve independent records)?
- How should our data be structured for that purpose?
- Which data store fits each use case best?
- If we have new processing requirements, would it be easy to use the data as it’s stored?
- If not, how complex would it be to transform it?
Our domain model should be designed in such a way that our most frequent, and relevant questions can easily be answered, and the data store type picked accordingly. This, in fact, is the reason for the proliferation of new data base systems being developed by companies to address their particular processing needs. Undoubtably, we should also consider other factors, like the level of expertise in our team when making these decisions. However, the questions, which should represent our project/business requirements, should be carefully weighed in when picking the right data store type.
In a future post, we will discuss data modelling with graph databases, in particular Neo4j database.