On an early post, I described a non-exhaustive taxonomy of data store types, as well as the types of problem domains each one was best suited for. On this post, I will address some approaches to modelling data in graph data stores, particularly with Neo4j.
Graph data stores have been increasingly adopted over the past couple of years in several business domains, ranging from logistics to bio-informatics. Their power lies in their ability to model complex networks and tree structures, with data points ranging from hundreds to millions of nodes and edges.
Coupled with visualisation tools, they make it easier for us to make sense out of data by looking at it, in a more intuitive way, easing the process of reasoning out solutions to certain types of problems.
The post is organised in the two sections:
- Graph’s Anatomy
- Objects, Places, Events
In the first section, I’ll talk about the building blocks of graph databases, i.e. their data elements and structure. In the second section, I’ll talk about how we can model different types of entities with those data elements.
Section I: Graph’s Anatomy
Just as we have tables and rows in SQL data stores, graph databases have their own data elements: nodes/vertices and relationships/edges. While the second pair of terms, i.e. vertices & edges, is the one often used in Graph Theory, since we’re talking from a data domain point of view, we’ll stick with the first pair, nodes & relationships. Nodes are the primary elements of a graph. They represent objects of our problem domain as independent entities, as rows do in SQL data stores. So a single node would stand for a car, a product, a building, or a text message. They can have properties that describe them, and some of these properties can be made unique so that no 2 nodes will share them. Relationships, on the other hand, represent relations between nodes in our graph. They connect all of our domain objects to one another, according to their actual relations.
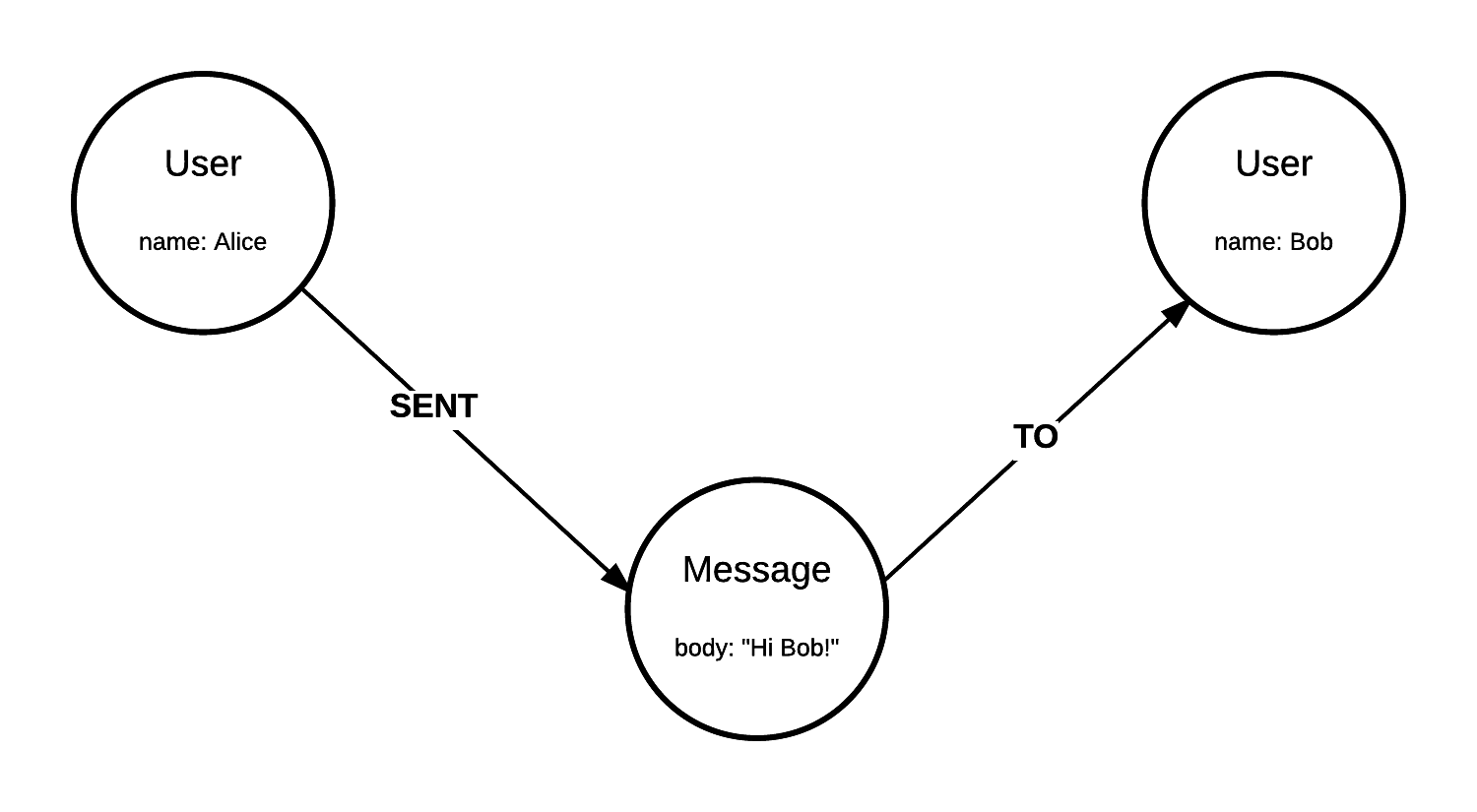 Figure 1. - Message from Alice to Bob.
Figure 1. - Message from Alice to Bob.
The equivalent of relationahips in SQL data stores would be relationship tables and/or Foreign Keys, depending on the nature of the relationship.
Both nodes and relationships can have properties. With them, we define the identity of our entities. More importantly though, they can have types. Types in nodes are what let us distinguish one domain object from the other, e.g. a User from a Message. Relationships also have types. Typically, a relationship can only be of one type, while nodes can be of multiple types. For example, and User on eBay can be registered as a Buyer and a Seller at the same time.
Neo4j is a graph database that we’ll be exploring in this post. It is an ACID compliant, non-distributed, disk persisted, and in-memory operating graph data store. In Neo4j, we can distinguish our entities through the use of labels in our nodes. When we assign a label to a node, we are defining their identity as an object of type X. Nodes can have multiple labels assigned to them, and this alone can make multi-tenancy domain modelling fairly easier. For example, two products from two stores, A and B, would both have the label Product. But one would have the label Store A, and other Store B. We’d make use of these labels to query the graph, limiting our search scope to the store of interest. Labels can be used in other creative ways to bound our search scope when running queries.
In and of themselves, nodes are not very useful to us in a graph. It is when we introduce relationships that we can start asking interesting questions. Neo4j supports directed relationships with properties, and they can also be bi-directional. Neo4j has its own querying language called Cypher. To create our graph illustrated in Figure 1 in Neo4j, using Cypher, we’d write the following:
CREATE (alice :`User` {name: "Alice"}), (bob :`User` {name: "Bob"}), (msg :`Message` {body: "Hi Bob!"})
WITH alice, bob, msg
CREATE (alice)-[:SENT]->(msg)-[:TO]->(bob)
Let’s start with the syntax. The CREATE clause is used to generate new entities. The WITH clause is there as a break, since a CREATE clause can’t be immediately followed by another CREATE clause in Cypher. On the first line, we create our nodes, Alice, Bob and the Message, represented in parenthesis, (); we also assign properties to them, using a JSON-like syntax. Note that alice, bob, and msg are just aliases for the nodes we’re creating. The text that comes following the colons, :, are the labels, and they define our node types. On the second line, we tell Cypher which of the entities from the first line we want to use on the coming lines, so it won’t discard them. And on the last line, we connect our entities with two relationships, represented in square brackets, [], and we define their types as SENT and TO. Note the lack of back-ticks as we define our relationships. While labels can have space and some other special characters, relationships can’t. So although Polar Bear is valid label in Neo4j, it is not a valid relationship type.
Our naive query will execute even if there are other Users in the system with the name Alice, and Bob, unless we define a unique constraint on the name property of User nodes. There is a great article by Luanne Misquitta titled Cypher MERGE Explained, on how to manage uniqueness with the MERGE statement in Cypher, at GraphAware. I strongly suggest reading it if you’ve started learning Cypher. The link is provided on the Help Articles section on the bottom of the page.
Now that we know what the data elements in a graph data store are, let’s have look at how we can model domains using them.
Section II: Objects, Places, Events
When deciding how model our domain objects in a graph database, the general rule is that objects (both living and non-living), places and events are nodes, and connections or relations are relationships. In other words, anything that refers to an entity will be a node, while anything that refers to an action or state will usually be a relationship. Let’s build another graph atop of the first to illustrate this.
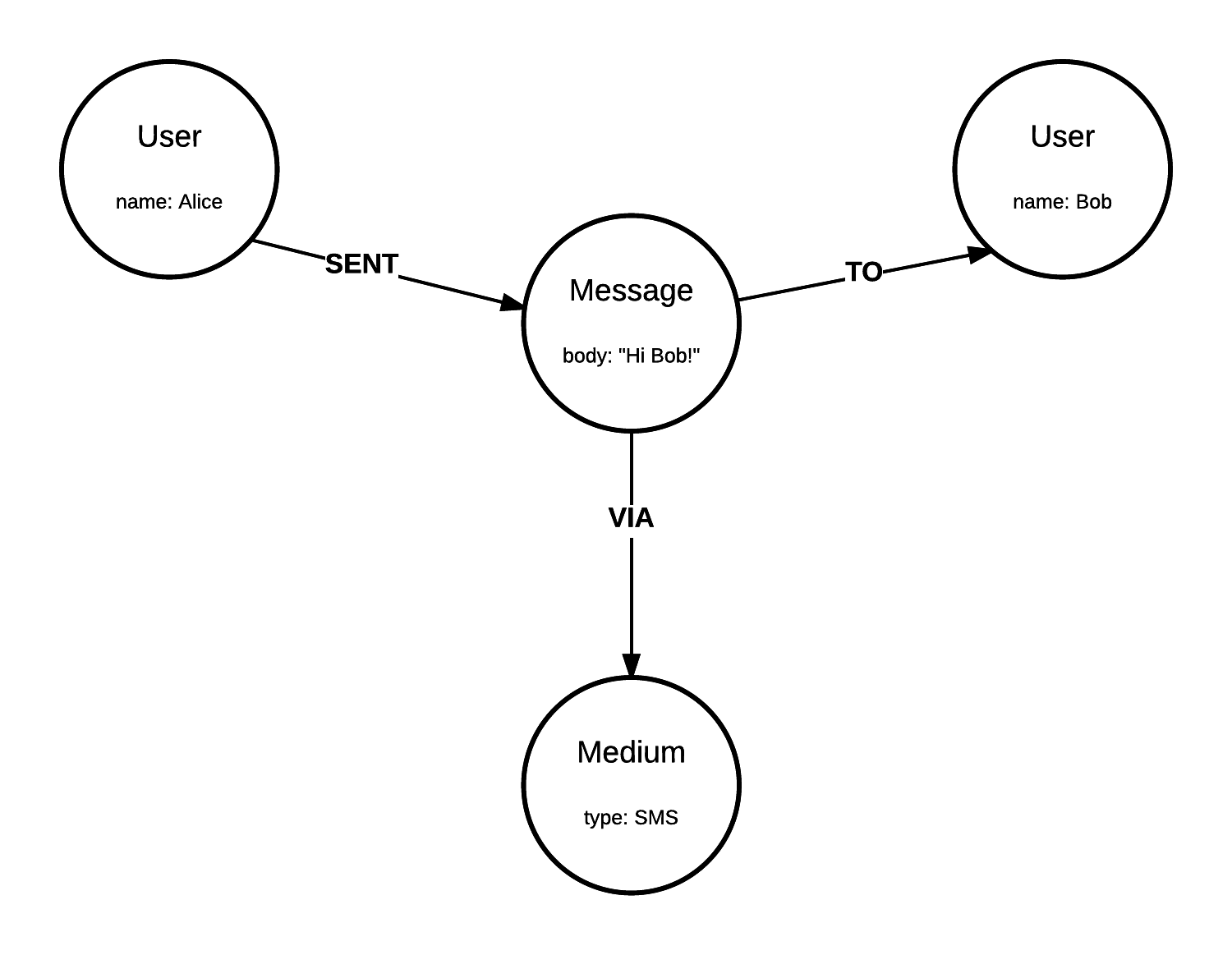 Figure 2. - Message from Alice to Bob, through a Medium.
Figure 2. - Message from Alice to Bob, through a Medium.
Reading Figure 2, we’d say Alice (who, entity), sent (do what, action) a message (what, entity) to Bob (who, entity), through (how, action) SMS (what, entity). Examples of other actions include delivered, constructed, and purchased; examples of states include to know, live/inhabit, and like. When deciding how to construct our domain through the lenses of a graph, some of these connections can feel really intuitive, even in complex domains. Nonetheless, it may not always easy to identify which of our domain objects are single unique entities, and if some “relations” are in fact entities by themselves, and should be represented as nodes instead of relationships. It is by thinking about the questions our model needs answer that we can model and re-model until we get out design right. We’re going to try and model two different domains to illustrate these challenges. The first domain will be an organisational chart, and with it we’ll address the challenge of identifying unique entities; our second domain will be a web-shopping user experience system, where we’ll observe the challenge of defining relationships and entities. After these 2 exercises, I will talk about modelling timelines.
Challenge I: Identifying Uniqueness
In our organisational chart, we aim to be able to answer the following questions:
- Who works in company X or department Y?
- What roles is a person assigned?
- Who is assigned a specific role?
- Who does a person report to under a specific role?
Attempt I
For our first attempt, we elect the following entities and relationship structures:
- Entities: Person, Role, Company, Department
- Relationships:
- (Person)-[ASSIGNED]->(Role)
- (Role)-[MEMBER]->(Company|Department)
- (Department)-[UNDER]->(Company)
- (Role)-[SUPERVISED_BY]->(Role)
We generate some data in Neo4j, using Cypher…
and come up with the following graph:
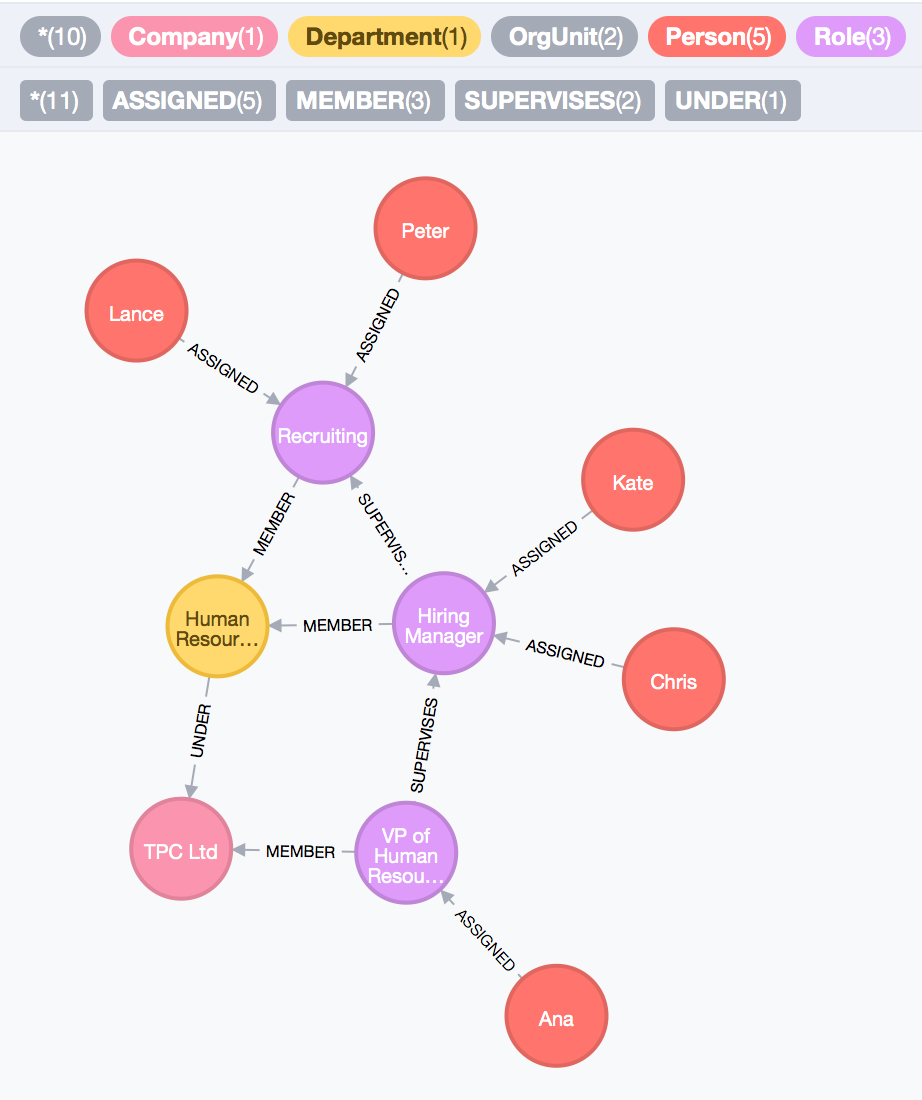 Figure 3. - Modelling Organisations, attempt 1. Screenshot from Neo4j browser visualisation tool.
Figure 3. - Modelling Organisations, attempt 1. Screenshot from Neo4j browser visualisation tool.
One of the first things we can notice is the complexity of the domain represented in a single view. The company and departments, the people working in them, their roles, and supervisory relations are depicted in the same way they are managed. Kate is a Hiring Manager, under the Human Resources department. Her department is under the TPC Ltd company, and as a Hiring Manager, she reports to the VP of Human Resources, Ana. Ana also supervises Chris, another Hiring Manager. Both Lance and Peter are Recruiting Agents, under HR. Now, let’s see if we can answer the questions we set out to.
- Who works under TPC Ltd?
Answering the first questions is fairly trivial task, with a cypher query:
MATCH (person :`Person`)-[:ASSIGNED]->(role :`Role`)
WHERE (role)-[:MEMBER]->(:`Company` {name: "TPC Ltd"})
RETURN person.name AS name, role.title AS title
Results:
| Name | Title |
|---|---|
| Ana | VP of Human Resources |
- What roles is Peter assigned?
The second question is of similar nature to the first; let us use the the following query:
MATCH (person)-[:ASSIGNED]->(role :`Role`), (role)-[:MEMBER]->(org :`OrgUnit`)
WHERE person.name = "Peter"
RETURN role.title AS title, org.name AS unit
Results:
| Title | Unit |
|---|---|
| Recruiting Agent | Human Resources |
The results of the first query tell us that Peter plays the Role of Recruiting Agent, under an organisational unit with the name Human Resources. In our gist, we assigned the company and department the label OrgUnit, as a way to allow us to query data for an organisational unit without knowing its specific type. In Neo4j, we can get the labels of a node with the LABELS(node) function. That function would tell us Human Resource has the labels OrgUnit and Department. We can also add a field named type to all organisational units in our model; that way, we could read the type of an unknown organisational unit directly. And while that field could be used in queries where we already know the organisational unit type, I think that labels are a much cleaner way of segregating node types, and limiting search scope. Note that if the role Peter was assigned hadn’t been a member of any organisational unit, the query would return nothing. To address this case, we’d modify our query as follows:
MATCH (person)-[:ASSIGNED]->(role :`Role`)
OPTIONAL MATCH (role)-[:MEMBER]->(org :`OrgUnit`)
WHERE person.name = "Peter"
RETURN role.title AS title, org.name AS unit
By making the MEMBER relationship optional, we can now get every role that Peter is assigned, including those that aren’t members in any organisational unit. You can learn more about Cypher from the Neo4j documentation.
- Who is a Hiring Manager?
This one is so close to the first, I’ll leave it as an exercise to the reader. It’s a simple question of reversing roles (pun intended).
- Who do Kate and Lance report to?
Let’s begin by formulating a query:
MATCH (person)-[:ASSIGNED]->(role :`Role`), (role)<-[:SUPERVISES]-(sv :`Role`)<-[:ASSIGNED]-(svPerson :`Person`)
WHERE person.name = "Lance"
RETURN role.title AS title, svPerson.name AS supervisorName, sv.title AS supervisorTitle
Before running this query, by making a visual inspection of the graph we can already predict the results. Kate should report to Ana as VP of HR, and Lance should report to… Kate and Chris?! See, both Kate and Chris are Hiring Managers; as such, they supervise Recruiting Agents. However, under normal circumstances, particularly in our fictional domain, each Recruiting Agent should report to one Hiring Manager. If we run our query for Lance, we’ll get the following result:
| Title | Supervisor Name | Supervisor Title |
|---|---|---|
| Recruiting Agent | Kate | Hiring Manager |
| Recruiting Agent | Chris | Hiring Manager |
So, under the role of Recruiting Agent, Lance reports to two people, Kate and Chris, who are both Hiring Managers. While this might be a perfectly valid scenario, what we have established is that the model we conceived cannot cater to cases where we want a Recruiting Agent to report to a single Hiring Manager. Tracing the problem to its source, we identify that our limitation is not in our entity types, or with the relationships we chose. It was brought on instead by the decision we made to represent a role once, regardless of how many people play said role in an organisation; more precisely, we considered a role “title” to be an entity, instead of the instances of the roles themselves.
To address our limitation, all we have to do is redefine the way we store data, and represent each role as played by someone as a unique entity.
Attempt II
In our second attempt to model our organisation, we’re going to maintain our entities and relationships in the same way we structured them in our first attempt. What we’ll modify is our data insertion approach, to consider each role played by one individual to be a unique node:
We have changed the names of the nodes with the same role title to distinguish them; but since MERGE looks at the property values to decide if a new node should be created or not, we must give nodes that share the title property a unique identifier for each; here, I added an id field. Let’s have a look at the generated graph:
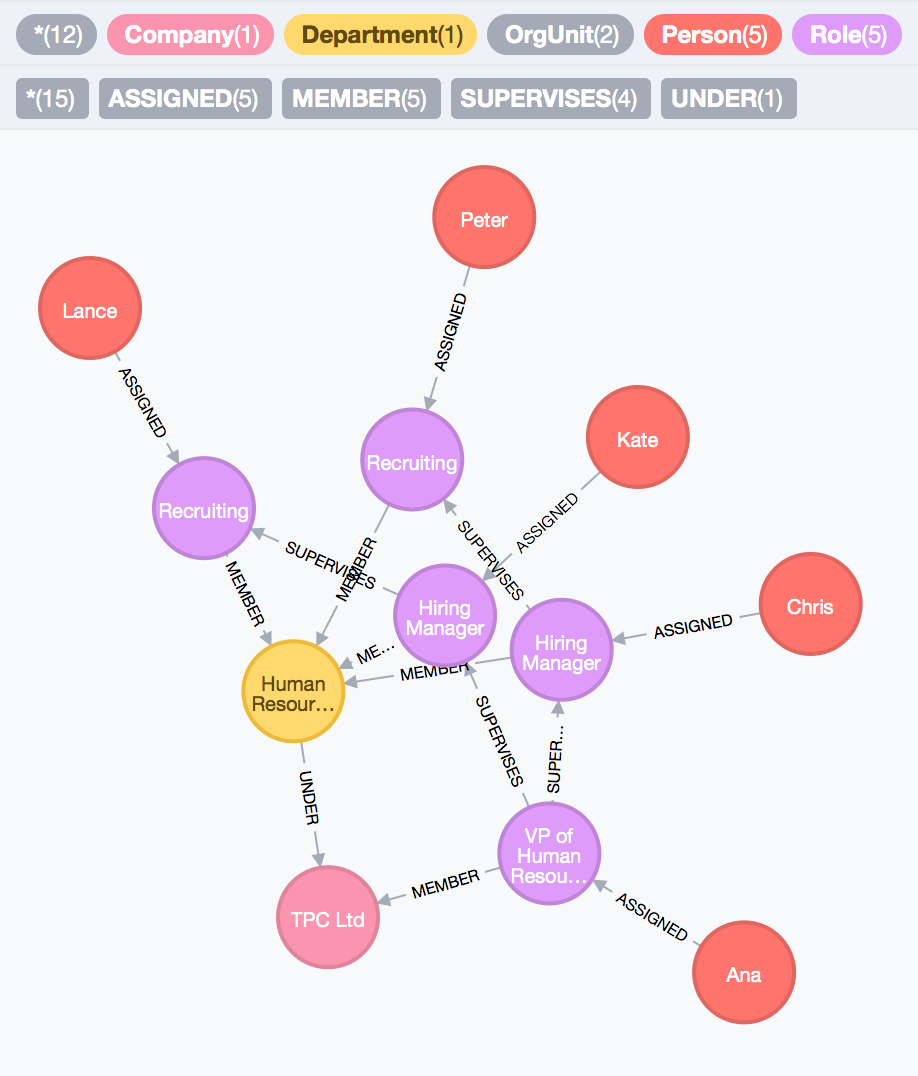 Figure 3. - Modelling Organisations, attempt 2. Screenshot from Neo4j browser visualisation tool/
Figure 3. - Modelling Organisations, attempt 2. Screenshot from Neo4j browser visualisation tool/
The new graph looks a little more complicated compared to the first. Let’s decipher it. Each Person has been assigned a role that is represented as a unique node. We still have one VP of HR, 2 Hiring Managers and 2 Recruiting Agents. Now though, it is clear that Ana supervises both Chirs and Kate as Hiring Managers, yet Lance reports to Kate while Peter reports to Chris only. This minor modification in our approach will allow to us address the problem of identifying unique supervisor-role relationships; By splitting instances of roles into their own nodes, we need more nodes to model our domain problem; this is the tradeoff we had to make to be able to answer our 4th question. Now, let’s have a look at our second modelling challenge.
Challenge II: Relations and Relational Entities
As I stated earlier, in most cases, actions and states can usually be represented as relationships. For example, (:Person)-[:SPEAKS]->(:Language), (:User)-[:LIVES_IN]->(:City); the action of speaking and state of living here can be both modelled as relationships. There are times, however, when the obvious mapping of an action to a relationship can be constraining, if not outright incorrect. The idea is that actions and states will not always be relationships in our graph. To illustrate this, let’s try and model a web-shopping experience tracking system.
When people shop online, they look at products they might be interested in buying. The most promising of these are added to a cart, and later purchased. Our goal is to track this user experience, for the sake of performing analytics, generating recommendations, and apply data exploratory analysis to create business intelligence, like spotting trends among customers. We could also be interested in product ratings; for this illustration though, the three first events will suffice; in fact, to keep things simple, we’ll just concentrate on the buy event for now. Let’s start by defining our entities, and relationships:
- Entities: User, Item
- Relationships:
- (User)-[:BOUGHT]->(Item)
Basically, we’ll be mapping out what what items our users’ buy within the system. Our data insertion queries:
Now, here is our sample graph with our first model:
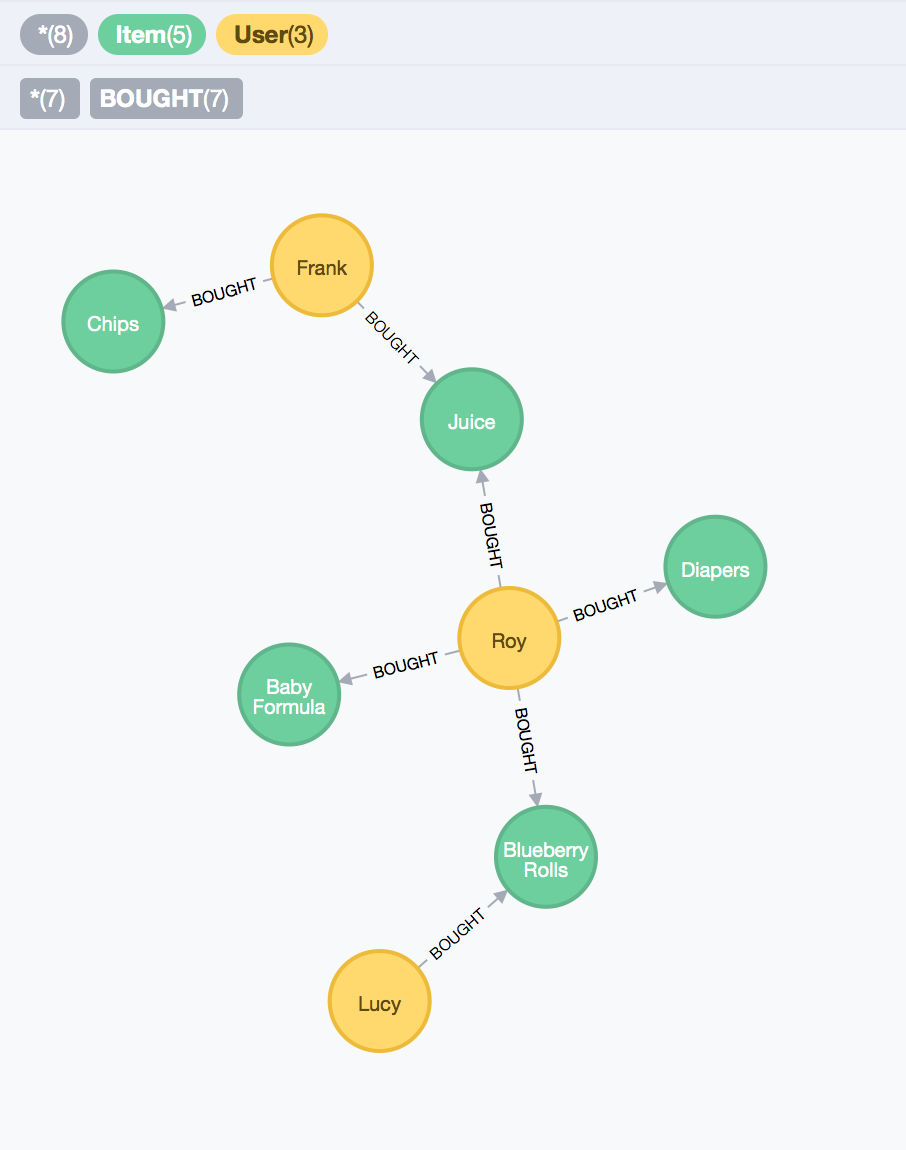 Figure 4. - Modelling User Web-shopping experience, attempt 1.
Figure 4. - Modelling User Web-shopping experience, attempt 1.
Each of our users has an item in common with at least one other user. In our insertion queries, there are timestamps that indicate when each event, buy in this case, took place. With this model, we are able to determine which users have shared interests. For example, Frank and Roy like Juice; and Lucy and Roy have a shared interest in Blueberry Rolls. Note that we can already recommend products to users based on this model. To recommend a product to Lucy, we’ll query the graph for products purchased by people who have purchased at least one product that she has.
MATCH (lucy :`User` {name: "Lucy"})-[:BOUGHT]->(boughtItem :`Item`)
WITH lucy, boughtItem
MATCH (boughtItem)<-[:BOUGHT]-(u :`User`)-[:BOUGHT]->(i :`Item`)
RETURN DISTINCT i.name AS item
LIMIT 5
Not surprisingly, our trivial example recommends Diapers, Juice, and Baby Formula to Lucy, which were purchased by Roy, the only user with a similar purchasing history to hers. While this result is valid, if we take a closer look at our gist, the timestamps for our events are different. For example, on the day that Roy bought Diapers and Baby Formula, he didn’t buy Juice. And when he did buy Juice, he only bought the Blueberry Rolls along with it. We know this from the fact that each order a client makes has one timestamp, for all items purchased in that same order. This shows a weakness in our model. We cannot easily know which items were purchased together, without matching the timestamps of the events, which can be computationally expensive and slow. A query for that would be like this:
MATCH (lucy :`User` {name: "Lucy"})-[:BOUGHT]->(boughtItem :`Item`)
WITH lucy, boughtItem
MATCH (boughtItem)<-[:BOUGHT]-(u :`User`)-[e :BOUGHT]->(i :`Item`)
RETURN e.timestamp AS timestamp, COLLECT(i.name) AS items
LIMIT 5
Our result returns the data segregated by timestamp, as expected:
| Timestamp | Items |
|---|---|
| 1431795131 | [Diapers, Baby Formula] |
| 1434473531 | [Juice] |
Note that the second result objects, i.e. items, were grouped based on the first object we return, the timestamp. This is how Cypher works. It takes the first element, and keeps compounding the following elements in our results based on their predecessor. This can make queries like the one above very intuitive.
Back to our model, while the second query is valid, it may not be the most efficient way of getting what we need. That is because we are using relationship fields to group data. It’s not hard to imagine that after 100,000s or millions of events tracked, our query would get slower with the volume of data to process. While there are ways to overcome this, and some of them will be discussed in an upcoming post, there is another approach we can take to limit our search field: add a node to group items purchased on the same order.
We will do this by introducing a node to our model, of type session:
- Entities: User, Item, Session
- Relationships:
- (User)-[:HAS]->(Session)
- (Session)-[:BOUGHT]->(Item)
We read our relational graph in the following manner: a user has a session, in which he or she bought items X and Y.
Using the same data as before, our model now changes to this:
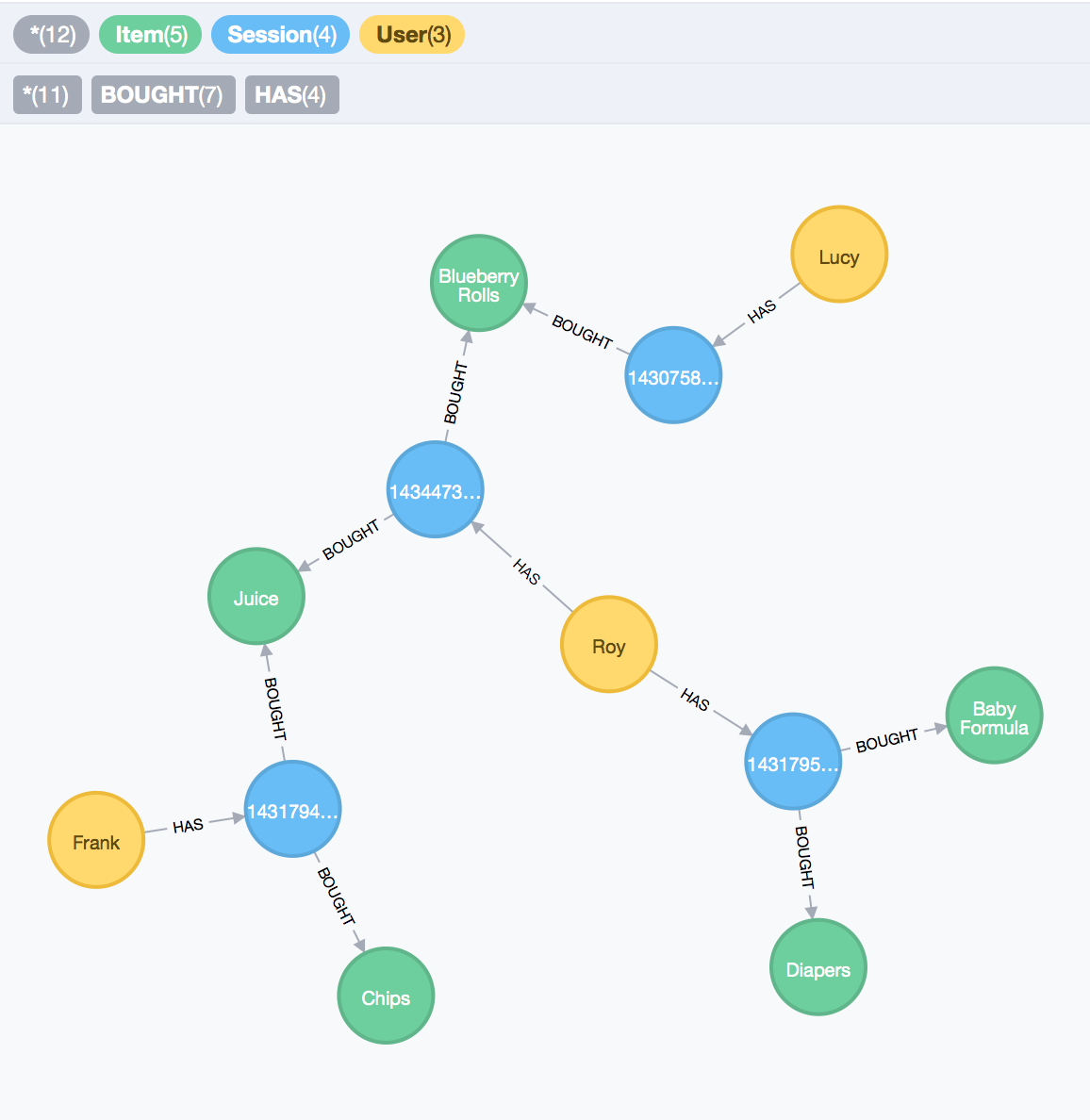 Figure 5. - Modelling User Web-shopping experience, attempt 2.
Figure 5. - Modelling User Web-shopping experience, attempt 2.
The timestamps on our buy events were actually indicators of a missing entity; our session, or order. This model is not only visually clearer, but also easier to query for relevant recommendations results because we now know which items actually go together. All that’s left to do now, is to modify our query to search within the ‘baskets’ of other users where the products that Lucy is interested in can be found:
MATCH (lucy :`User` {name: "Lucy"})-[:HAS]-(s :`Session`)-[:BOUGHT]->(boughtItem :`Item`)
WITH lucy, s, boughtItem
MATCH (boughtItem)<-[:BOUGHT]-(s1 :`Session`)-[:BOUGHT]->(i :`Item`)
RETURN DISTINCT i
LIMIT 5
The query above returns just one result: Juice. It is the only product that was paired with Blueberry Rolls in another user’s basket, and thus, it is likely to be more relevant than Diapers and Formula, for this use case. Note that in a practical scenario, we’d need to take the list of results, and rank them to see which items appear more times paired up, or find a way of computing similarity between items. The goal of this naive scenario is to showcase how a change in our graph’s model can make searching for relevant results easier; additionally, we can understand user’s buying trends, and observe their change over time, with minimal computation compared to our fist model, the trade-off being the addition of more nodes in our graph.
Timelines & Sequences
Sequencing can be a relatively easy concept to model in Neo4j, depending on what we’re trying to achieve. In fact, there is a graph gist by Kenny Bastani on how we can model dates in an actual timeline, so we can traverse our graph in sequence going backwards or forward in time; I’ll leave it to the reader to the explore the gist, and experiment with it. On the last section of this post, I’ll just briefly talk about a particular use case in event modelling: when we wish to sort events by timestamp. Our last model for tracking the web-shopping experiences of our users had a Session entity with a timestamp. While this works for our modelled event, buying, when we introduce other events into the mix, like VIEWED and ADDED_TO_CART, the timestamp on the Session node starts to make less sense. See, while Session would have a timestamp, a user would view, add an item to cart, and buy them at different times. So, we need to find a way to sort these events, individually, based on their timestamp, if that’s what we’re interested in doing.
While an immediate idea to solve this might be to add the timestamp to the event’s relationship itself, this would make querying hard, and exhaustive, as relationship properties are not indexed in Neo4j 2.x. So, perhaps not surprisingly, we’re left with the option of turning those event relationships into nodes:
- Entities: User, Item, Session, Event
- Relationships:
- (User)-[:HAS]->(Session)
- (Session)-[:CARRIED]->(Event)
- (Event)-[:VIEW|ADD_TO_CART|BUY]->(Item)
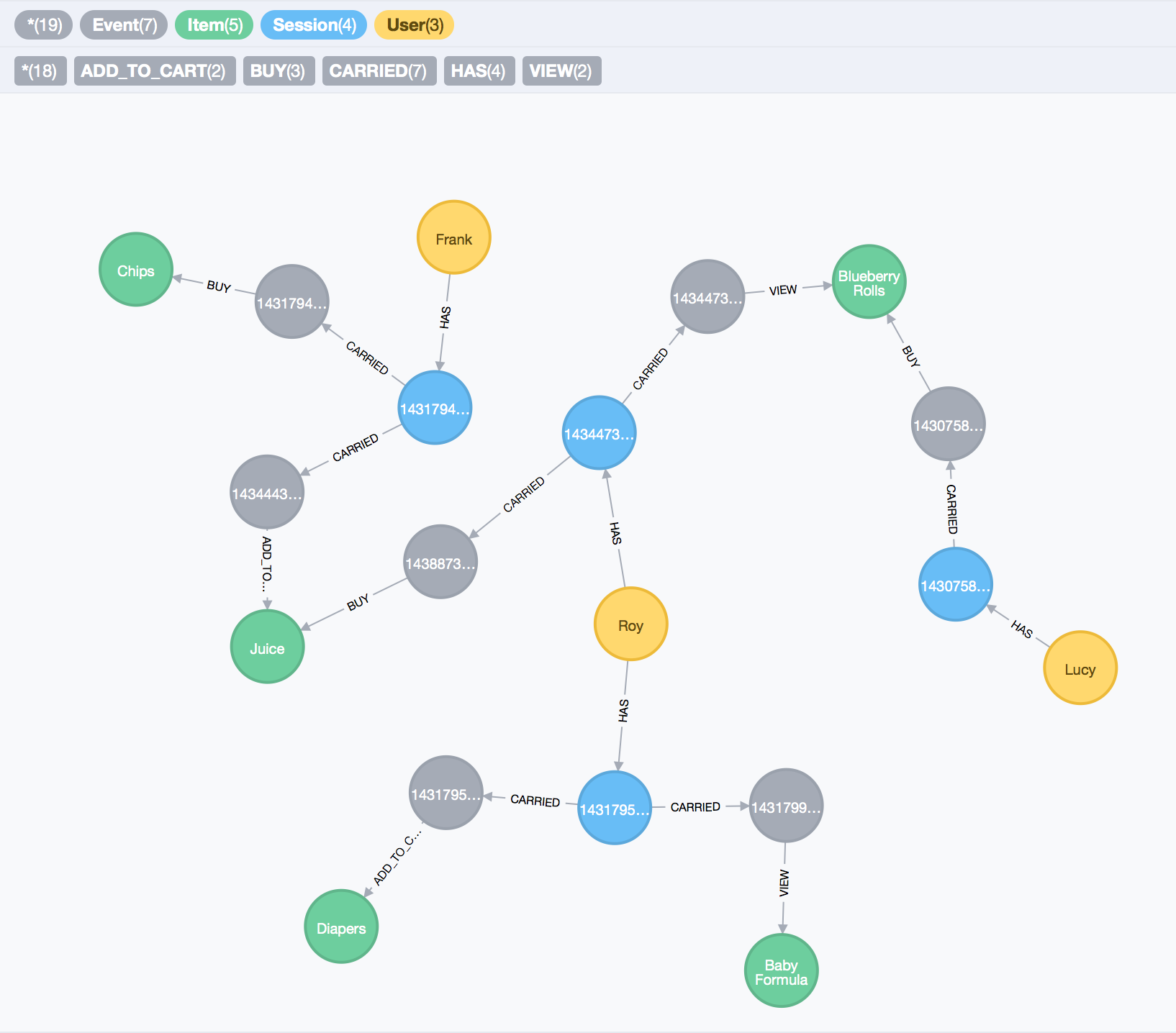 Figure 6. - Modelling User Web-shopping experience, Time Sorting.
Figure 6. - Modelling User Web-shopping experience, Time Sorting.
Our graph has grown three to four times the size of the first. And the paths between items have also gotten longer. In theory, path traversal length does not have a great impact in performance in Neo4j. Nonetheless, I’d say that this latest modelling approach should be applied only if sorting events is of vital importance, e.g if we want to know what our most recently viewed or purchased items are. Though another approach to this problem would be to keep this kind of information in a separate data store, where we’re keep events for a fixed period of time, e.g. 24 hours, to avoid data duplication. Also, if we were only interested sorting the time of orders, we could group buy events under one Order or Basket node, and leave our other events as they are. These would be, in my opinion, more viable solutions to the problem of sorting events in our model.
Summary
Graphs data stores have two basic data elements: nodes and relationships. The first represent objects in our domain, while the latter is for the relations between them. While certain problems may seem, and actually be, obvious to model in graph, there can be challenges in defining how to manage our data that we must pay attention to, e.g. in representation of uniqueness of relationships between nodes, and determining when we have a relational node instead of simple relationship. In the end, it’s our domain questions that drive the changes in our models, and we should iterate our design until we get it right. In a future post, I’ll present some use cases that graphs are good for, and discuss about how we can maintain performance in Neo4j, especially when our data volume grows.