In this post, we are going to use text analysis tools UIMA and OpenNLP to identify film personas, like directors and screenwriters, from a corpus of movie reviews.
Warning: Working knowledge of Java is necessary for completing this guide.
Estimated required time: ~60-90 minutes
Overview of Natural Language Processing
Since the 70s, experts and businesses had realised the potential that exists in gathering, storing, and processing information about their operations to add and create new value for their organisation and their customers. During the first few decades though, the focus was set on structured data.
What is structured data?
Structured data is basically organised data, with fields that have a clearly defined type (e.g. numeric, text), length, and with other forms of restrictions, such as range (e.g. age ranges from 0 to about 120, for really healthy people). Structure is vital for computers. Since they ultimately only understand 0s and 1s, we need to format data in a way that makes it easy for computers to process. Without digitizing data, a task like calculating the total sales of Amazon in a month across all of its operating regions would take more time and human resources than we could afford to expend. I have discussed some of the most common data store types where we can keep this structured information.
The opposite of structured data is unstructured data. You can think of unstructured data as data that is normally produced by people to be consumed by other people. Take an email, a tweet, or a blog post like this one, for example. Now, an email does have a heading, a body, and one or more recipients. Likewise, a tweet can contain hashtags, a location, language fields, and a blog post can have tags. These fields give a semi-structured nature to these entities, or documents as we shall refer to them here. However, the most relevant piece of data in these documents are the messages written to be read by others. By having the title and tags of this blog post we could, for instance, search for other blog posts on the Web that have the same tags, assuming these would mean they are similar. However, without understanding the content of the blog itself, it is almost impossible for us to determine which of the posts are closest, or cover the same topic lines. The bodies of these documents, which contain this very critical piece of information are neither structured in format, length, or nature. Likewise, we can look at images and video in the same way.
Unstructured data does not only exist in the digital world. Physical books, research papers, and magazines are also forms of unstructured data. Generally though, we tend to focus on the ones that reside in the digital sphere because they are easier to acquire in order to process. So, what do we do with a stack of (digital) documents? We could just ignore them, as was done for years after the explosion of knowledge discovery and data mining. However, today we have tools that can allow us to store, process, analyse, and extract valuable knowledge from them. Hence, there is great deal of focus in data science and technology to create systems that are not limited to structured interactions, but instead go beyond to provide natural language experiences to users.
In the universe of data science, natural language processing, or NLP, is one the many oceans, with its own islands. This field has seen wide growth over the past ten years, with the improvement of research that has contributed to numerous tools which have been applied to different domains, such as personal assistants (e.g. Siri), medical enquiry systems, and even in journalism and literature, where algorithms, or ML models have been shown capable of writing books and poems. NLP is concerned with understanding spoken, and written human language (parsing), reading scanned documents and photos (OCR), language generation (Siri responding to enquiries), information retrieval (Google Search), sentiment analysis, and other areas of research concerning human language and machines. But how does this all work?
There are many different aspects to NLP, and each deserves careful attention and study. Our goal here today is to showcase how we can use some tools to extract information from unstructured documents. We will do this by using two specific tools, UIMA & OpenNLP, to help us identify film personas from movie reviews. Now then… lights, camera, action!
Environment
In order to follow this tutorial, you will require a working Java environment. To use UIMA’s visual tools, you will need UIMA installed on your computer. Installing UIMA is beyond the scope of this tutorial, and you can refer to the UIMA installation documentation guide on how to do that. To run the code, you should have Maven installed. The code can be downloaded from github. To create an annotator, I suggest you make use of UIMA’s plugin for eclipse, as it can considerably reduce the number of steps you need to perform yourself.
Tool set
It is time to introduce the tools we’ll be using for this task.
UIMA
UIMA, which stands for Unstructured Information Management Architecture, is an Apache project that spawned from IBM’s effort in developing a common platform for content analysis. You can read about it from its web page, and other web sources. For the purposes of this post, you need only understand that UIMA let’s us define a pipeline to process data. We generally feed it unstructured data, and it churns out structured data, by following a set of steps that we define. UIMA pipelines can be very rich, or very simple, like the one described in this post. We will use UIMA perform named-entity recognition (NER), one of the tasks NLP is concerned with. NER is a process of extracting identified instances of classes from content. For example, the task of searching for and extracting IP addresses from log files can be considered and NER task, and it can be very useful for organisations, and personal projects as well. If we were extracting IP addresses from our server logs, then the entities for us would be the the servers or client IP addresses, and we would identify them by looking for IP patterns using for instance regular expressions, as we will do here.
UIMA is normally used to annotate text. What this means is that it creates metadata files that describe where in the text some pattern we are looking for was found. To make annotations, we need to create annotators, and defined a UIMA pipeline where our documents will be the input, and out of which we will get the annotations we seek, if they are found.
Note: if you are not familiar with regular expressions, you can refer to the wikipedia page link I provided. They are a very useful for pattern search in computing.
OpenNLP
OpenNLP is a Java based library for natural language processing. We will use it here to perform part-of-speech (POS) tagging, another NLP task. POS tagging is the process of identifying the grammatical category of each word in a sentence, and it is normally performed over a corpus (read collection of documents) when performing NER because it makes it that much easier, and we’ll be seeing how.
The Problem
We want to identify film personas from a corpus of movie reviews. The data set I used for testing was prepared by Bo Pang and Lillian Lee, and it can be downloaded from here.
This data set contains positive and negative reviews of films, and it was curated for sentiment analysis. Here though, we’re only concerned with identifying the actors, screenwriters, directors and other film personas mentioned in the reviews, and the data serves well for that. We will be making use of a small subset of the data for testing our program.
All files in the data set are .txt files, and the text is all in lowercase. You can see what pre-processing was done on the data on the curators web page I provided.
Strategy
When performing NER, the general strategy is to get familiar with the corpus we’re processing, and identify patterns that can help us spot what we are looking for. This part is usually the longest part of any text analysis project, but if performed correctly then we can yield better results at the end. We have to read several samples of the documents, and try to learn patterns how they are written, and how references to the entities we are interested in are made. Once we have identified those patterns, we run a text search, using for example regular expressions, to extract the patterns we are looking for. For instance, if we are looking for dates in a corpus of historical documents, and we see that the pattern “in the year xxxx” appears commonly, we build a regular expression to extract all occurrences of that pattern from all documents in our corpus.
Now, simple regular expressions are powerful on their own. But, if we were to only rely on them, we’d have higher chances of getting false positives. Imagine the following scenario: one of the patterns identified in the text is "created by ([A-z]*)", which in most cases identifies a movie director. But in some files, we can find the pattern “created by the same people…”; extracting the words the or the same and annotating them as movie directors would clearly be a mistake. That is why it is important that we make use of POS tagging first, and run our pattern search on annotated documents.
Just to give you an example of POS tagging, if we were to POS tag the sentence “It is a beautiful day!”, we would get the following result:
It/PRP is/VBZ a/DT beautiful/JJ day/NN !/!
In the tagged sentence, PRP stands for pronoun, VBZ for verb, DT for determiner, JJ for adjective, and NN for noun. “!” is a punctuation mark, and it is identified as such. You play around with the online POS tagger to test any sentence and see how tagging works.
Now, going back to the previous scenario, knowing our text was POS tagged, we could boost our regular expressions to take into account the grammatical context of the data, and change our earlier pattern into a better one: "created/VBN by/IN ([A-z]*)/NN ([A-z]*)/NN"
With this new regex, we can prevent the word the from being identified as a director when it appears next to the words “created by”, since it is not a noun. Although this would not ensure 100% accuracy, it would diminish our margins of error significantly, and that’s why we’re going to apply it here.
Creating Types, and Annotators
To perform document annotations with UIMA, we need to create annotators. An annotator, in UIMA, is a class that performs the logic of annotating document. In our case, the annotator I defined, named PersonAnnotator, is going to search each movie review file to find actors, cinematographers, and other movie personas. Each entity that we find in our text is an annotation. In UIMA, an annotation is a type, a class that represents an entity, e.g. Actor. As a class, it has its own properties, which we can specify when we define it. We can have as many annotations as we need; If were interested in events, for example, we could record their name, place and location in the same entity, or create a separate entity for each depending on our needs. I have defined 6 types for this tutorial: Actor, Cinematographer, Director, Fictional Character, Screenwriter, and Person. The last one is for when we identify a person’s name, but we can’t tell what kind of movie persona they are, like with the pattern ‘oscar/NN winner/NN ([A-z])/VBG ([A-z])/NNS’, since an oscar winner can be a director or an actor, and other film related roles. Our types are defined in something called a type system in UIMA.
Type Systems
We define our types in a file we named PersonTypeSystem.xml, under the desc/types/ folder of our project. Using the eclipse plugin is the easiest way to create types, we get a window that looks like the following:
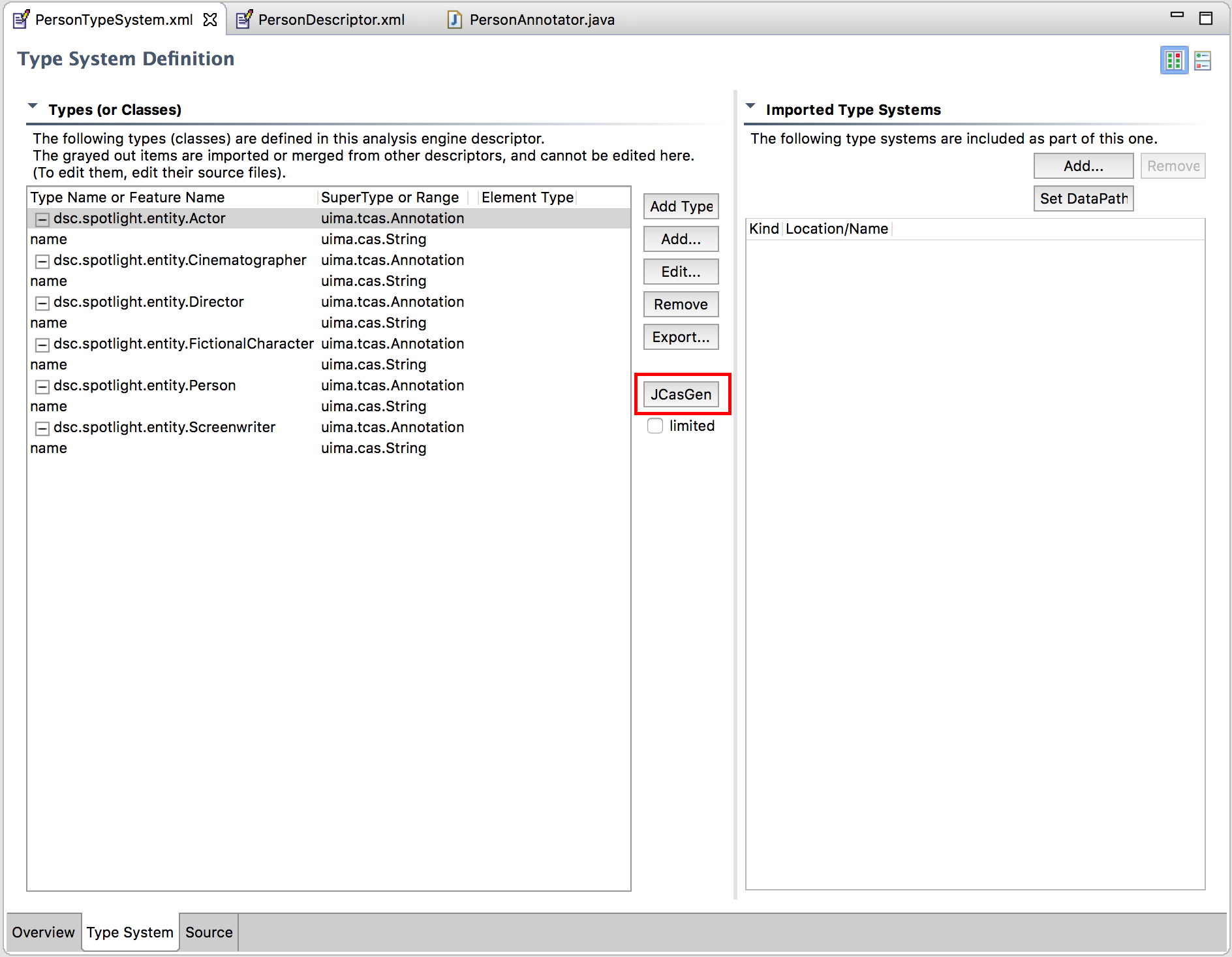 Figure 1. - UIMA Type System Editor in Eclipse.
Figure 1. - UIMA Type System Editor in Eclipse.
To add a new type, click the “Add Type” button, and add a full class name to your liking. I used dsc.spotlight.entity as the package name for all types. When you select a type, you can add fields with the “Add” button. You will get another window form to fill the field’s name and you’ll also get a list of types supported by UIMA, e.g. String, StringArray. I defined a field name of type string for all 6 types.
With all types defined, we’re ready for the magic. Click on the JCasGen button. The UIMA plugin for eclipse will generate the classes for each of these types. If you glance the source code files, you’ll see that the code is filled with a lot of boilerplate required by UIMA, and this is why I strongly advise that you use the plugin.
Now that our types have been generated, we can code the logic find the entities we seek in movie review files.
Annotator
The annotator is the component that contains for logic for a specific annotation. To create an annotator, we create a class that inherits from org.apache.uima.analysis_component.JCasAnnotator_ImplBase in our project. This class defines two methods that we can override: initialize, and process. In the first, we can place that to be executed when the instance is created, and the other will contain code to be executed for every document fed into the pipeline.
In this class, we place logic to load a list of regex patterns from UIMA’s context variables, search for each regex pattern in a document, and create annotations accordingly. Before applying the regex pattern though, we POS tag each line of the document, using OpenNLP’s POS tagger for the English language. You can browse the dsc.spotlight.annotators.PersonAnnotator file for details.
Analysis Engine
With a type system defined, and our annotator created, we are ready to create an analysis engine, i.e AE. In UIMA, an AE is a data processing pipeline. It is here that we define what annotator, or annotators we want to use, and load the type system with our annotations. In addition to this, we can also specify context variables that will be fed to our annotators when they are instantiated. I used these variables to specify a list/array of regex patterns I want to use, as well as the location of certain language files required by OpenNLP. This allows me to modify the files, and/or regex patterns without recompiling code, which is really practical.
The AE descriptor file was created under the desc/ folder, and I named it PersonDescriptor.xml.
 Figure 2. - UIMA AE Editor in Eclipse - Overview.
Figure 2. - UIMA AE Editor in Eclipse - Overview.
The following is a caption of parameters definition
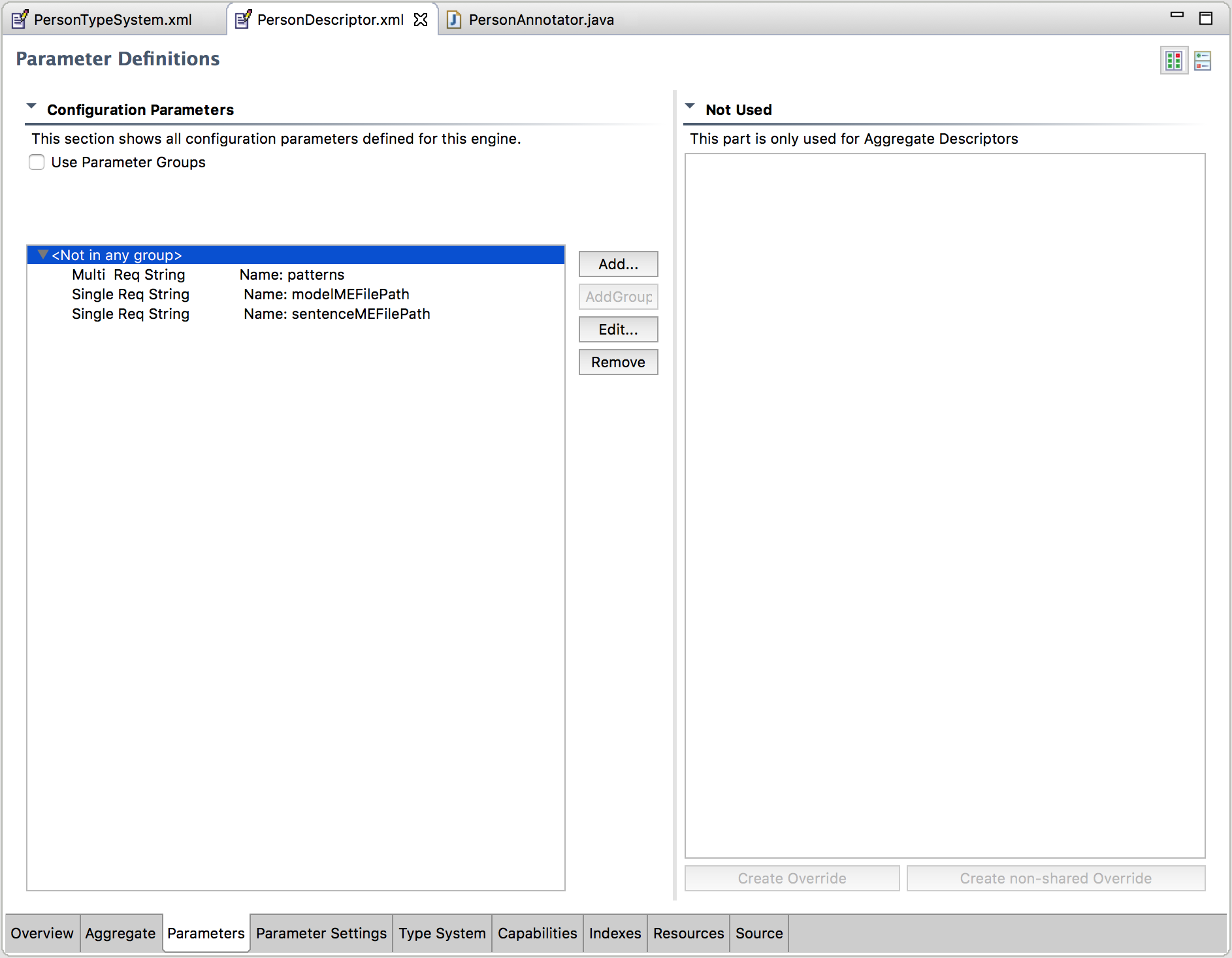 Figure 3. - UIMA AE Editor in Eclipse - Parameters.
And next, a caption of parameters setting
Figure 3. - UIMA AE Editor in Eclipse - Parameters.
And next, a caption of parameters setting
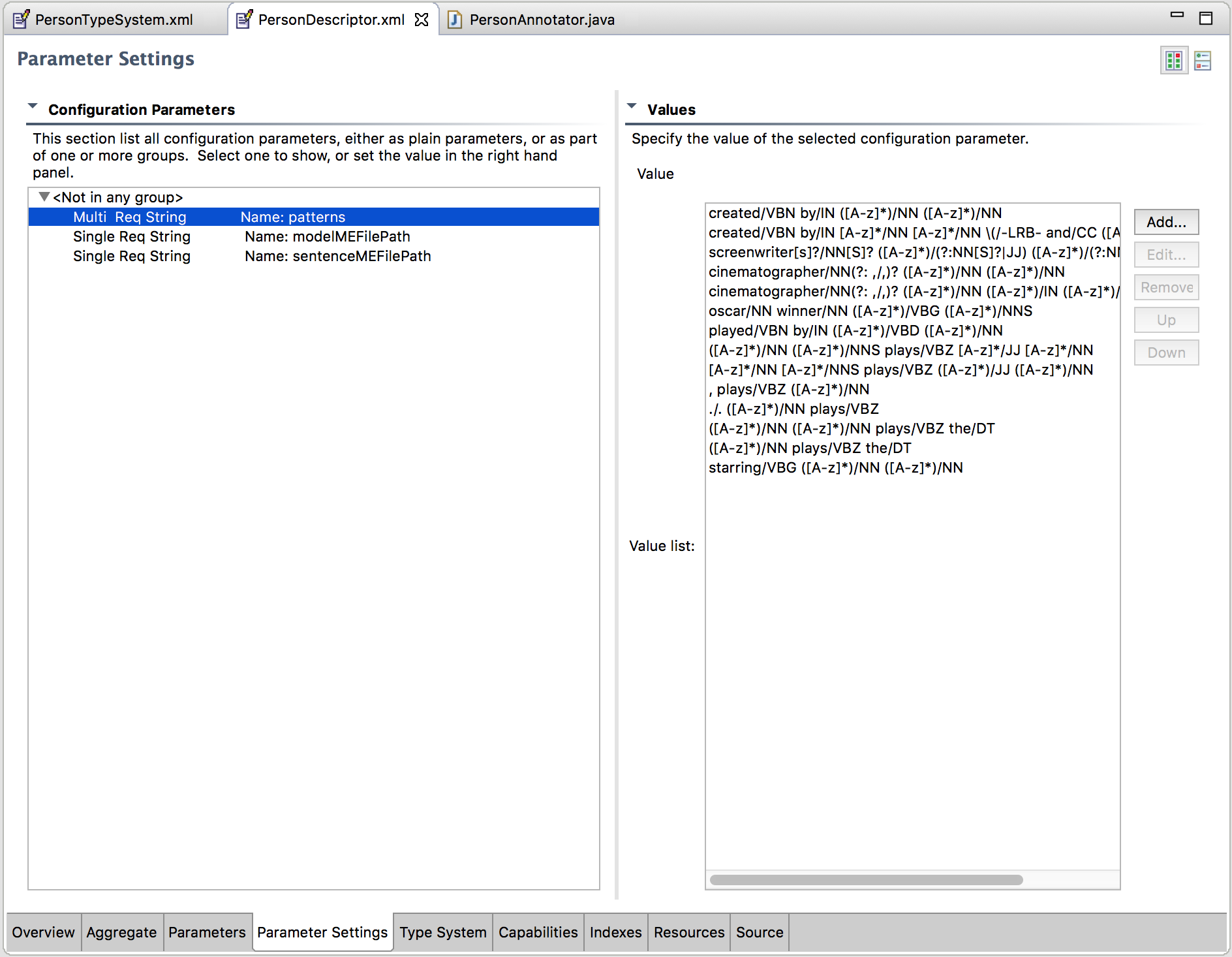 Figure 3. - UIMA AE Editor in Eclipse - Parameter Setting.
Figure 3. - UIMA AE Editor in Eclipse - Parameter Setting.
And finally, the type system specification.
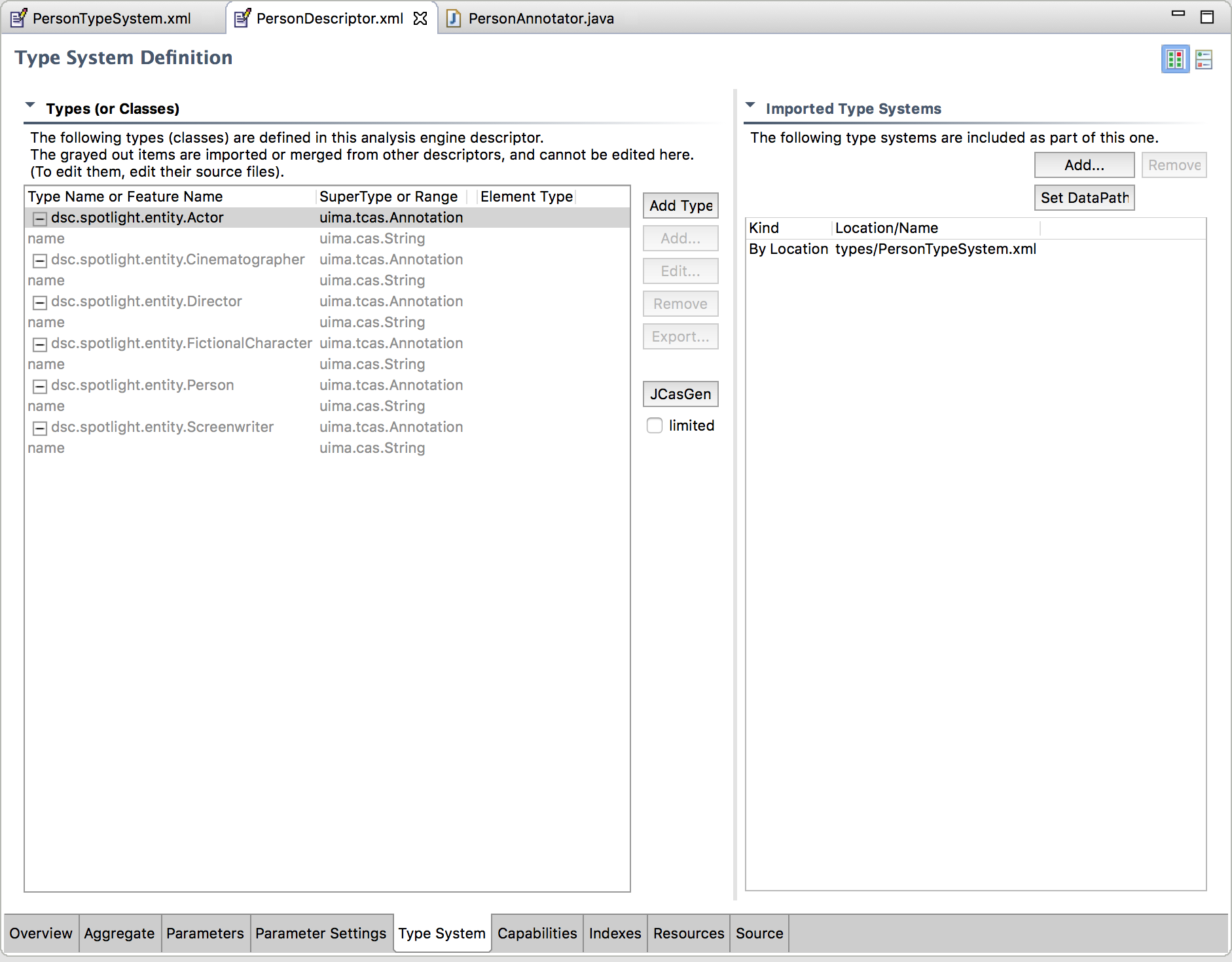 Figure 4. - UIMA AE Editor in Eclipse - Type System.
Figure 4. - UIMA AE Editor in Eclipse - Type System.
With this last step, we are ready to package our AE for use. We’re going to test it using some tools that UIMA provides for testing annotators. To build the project with maven, run the following command:
mvn clean compile assembly:single
Named Entity Recognition
As explained above, the logic for our annotator is simple: grab a line of text from a review, POS tag it, search for the regex patterns we provide, and if entities are found, annotate them according to the logic we specify in our annotator.
Analysing Documents
To analyse our corpus, we’ll use UIMA’s provided documentAnalyzer tool. Before running it though, we have to set the classpath in our environment to point to the folder where our built jar file is located:
export CLASSPATH=~/{path-to-source-code}/spotlight/target
And now we can run documentAnalyzer.sh:
bash $UIMA_HOME/bin/documentAnalyzer.sh
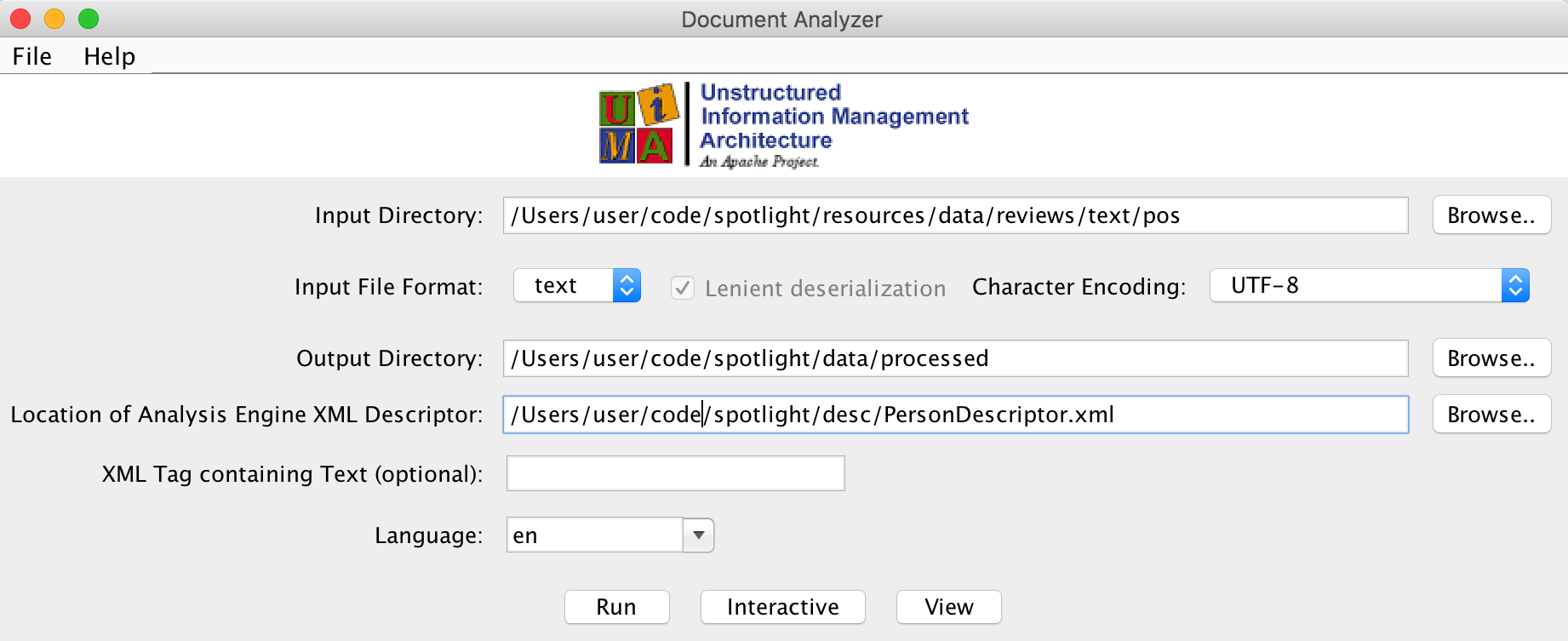 Figure 5. - UIMA Document Analyzer.
Figure 5. - UIMA Document Analyzer.
Once we set each of the parameters required, we click on the run button, and all documents in our Input Directory will be fed to our AE. The results are displayed in a list box, where we can select each document to see what entities were found, if any, in each of them.
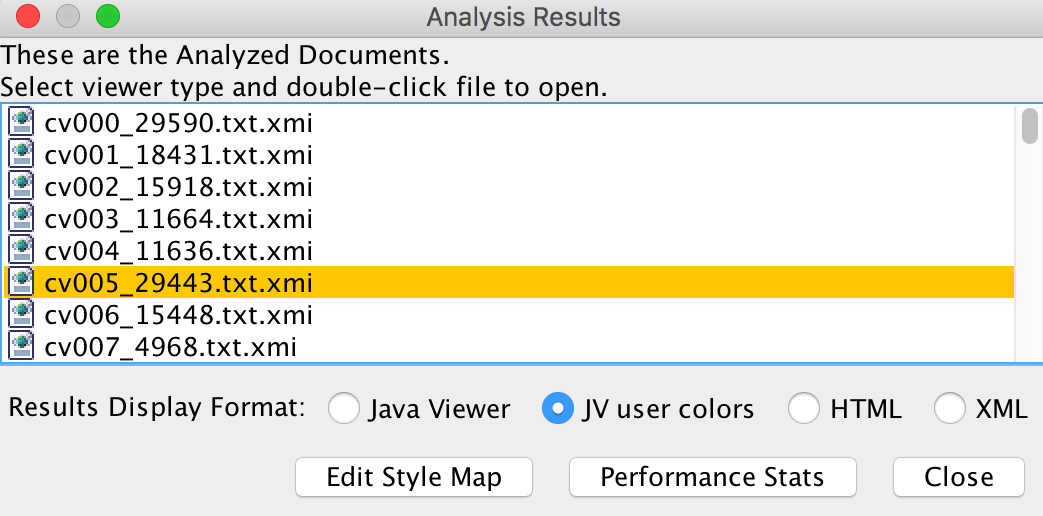 Figure 6. - UIMA Analysis Results.
Figure 6. - UIMA Analysis Results.
Each xmi file contains the CAS (common annotation system) for a document, i.e. an XML structure that describes the entities that were found, as well as their location in the document. Common attributes include id, begin, end, and sofa which represent the ID of the annotation, begin and end positions where the annotation was found in the document, and the ID of the document where it was found, respectively. The file also contains the fields that we extracted, which in this case was just the name of the entity. Double clicking a file opens a CAS viewer. The viewer gives us an overview of what annotations were found, and highlights each annotation in the document. If you’re having trouble visualizing annotations with the viewer, you can run the CAS viewer directly from the terminal:
bash $UIMA_HOME/bin/annotationViewer.sh
We specify the Input Directory, where our xmi files are located, and a path to the descriptor file:
/Users/user/code/spotlight/desc/PersonDescriptor.xml
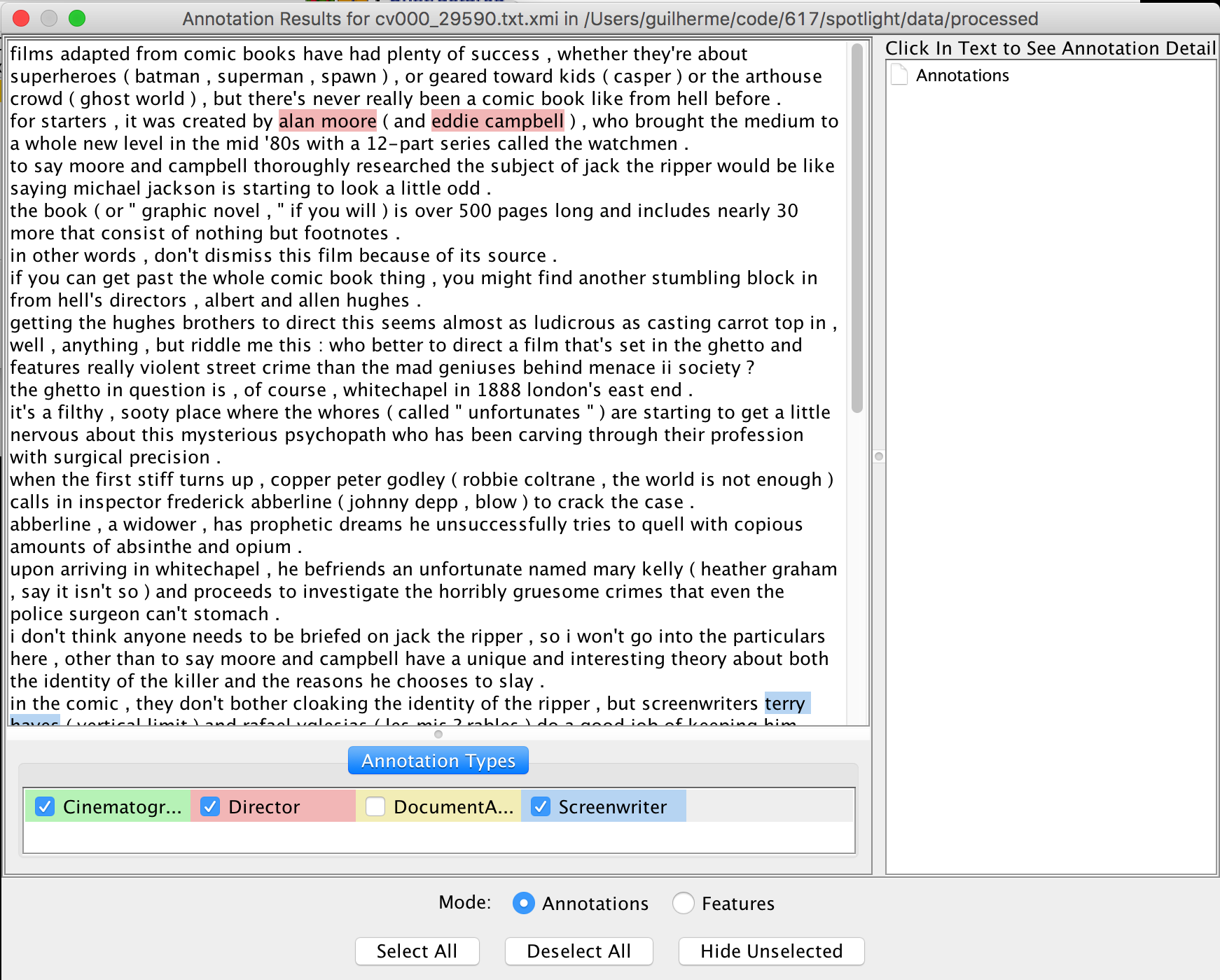 Figure 7. - UIMA Annotation Viewer.
Figure 7. - UIMA Annotation Viewer.
As you can see, we managed to identify at least one cinematographer, director, and screenwriter in the first document. The viewer highlights the entities using the begin, and end fields in the xmi files for each annotation found, so we can see where they are located. And that’s how we turned unstructured corpus of reviews, into a structured one, by adding metadata that provides vital information for easier or more convenient processing and querying.
Closing
In this post, I tried to introduce you to one of the tasks in NLP: Named-entity recognition, or NER. We used UIMA, a document processing engine, coupled with OpenNLP, a Java NLP library to identify film personas in a corpus of movie reviews. The benefits of using UIMA is that you build complex data processing pipelines that can evolve with time, and as an output you get structured metadata that is ready to be further processed. You can use the approach I used here to perform other kinds of NLP related tasks on documents, and combine it with other tasks to extract, and analyze rich data sets. In a future post, I’ll demonstrate how we can take a corpus of annotated documents, and make them searchable, so you can easily find relevant information.