It’s Monday morning, and you just got up. You look at the clock, and it tells you the time is now 7.45am. You have a presentation that starts 8.30am, so that gives you exactly 45min to get to the office. Now, you have a few decisions to make here. Breakfast, yes or no? Mode of transportation, bus, metro or biking? Clothing preparation, i.e. throwing on last week’s shirt or ironing new clothes? Each decision will affect your timeline. For instance, breakfast could take up an extra 15 to 20min, between preparation and eating. This will give you less time for other things, and could make you potentially miss the bus. Furthermore, missing the bus could make you late, which would leave a bad impression. On the other hand, arriving hungry could be problematic because you wouldn’t be as sharp as you could be during the presentation. Let’s put aside the fact that you should have just gone to bed and woken up earlier in the first place. The fact is, you now have decisions to make to attain a specific goal, which in this case could be carrying out a good presentation, or just not being late for starters. Each choice leads to other alternatives. Some are expanded, and others dissapear, e.g. missing the bus. As you think about these decisions, you are mentally evaluating your chances of success on the final outcome.
This exercise of estimating probabilities in stochastic events, is what we try to do with machine learning.
Machine learning methods have as one of their underpinnings probability theory. There are two kinds of probability theories: frequentist, and bayesian. The former deals with repeatable events, while the latter deals with degrees for belief. For instance, if one were to toss a fair coin, there would be 50/50 chance of getting either heads or tails. What this means is that if we repeat this event, the tossing of a coin, several times, we’d still have the exact same likelihood of getting one outcome or the other, assuming we have a fair coin. Bayesian probability, on the other hand, is used to express a qualitative level of certainty about an outcome. For instance, given the current time, bus schedule, and my breakfast-speed (yes, there is such a thing), how likely am I to eat, and still arrive on time. Despite their differences, both of these share the same approaches to problem solving.
Every phenomena that originates from either nature or human activity, can be said to have an underlying distribution. For every factor that influences a phenomenon, there will be a set of ‘rules’ that guide the interactions between said factors, leading to a given outcome. For instance, if someone is exposed to certain level of radiation from the sun, for a certain period of time, they could suffer from adverse skin problems, and perhaps even contract cancer. Whether they will, or not, and the type of cancer they would contract would depend on the host of factors: prior exposure to radiation that left them vulnerable (e.g. X-rays); the type of skin they have; the level of radition ingested, which would in turn depend on where they are in the world, and the inclination of Earth towards the sun at the time of exposure, and so on.
To paint picture, let us imagine that there is a junction between all of these factors where the likelihood of contracting skin cancer will be higher. For instance, if a person has had a battery of X-ray tests for the past couple of months, and yet they live in an area with little exposure to sunglight, then their chances of getting skin cancer could be lower. Conversely, a person that lives is a predominantly tropical climate region, where they are regularly exposured to high temperatures, could have higher chances of getting skin cancer. However, exposure alone would not be deciding factor, since knowing that you are at higher risk can actually make you take preventive measures. Note that I am not an expert in skin, or any other type of cancer for that manner, nor have I realied on statistical facts for this mental exercise. The point here is that there variables are play, whose values tilt the outcome in one direction or the other.
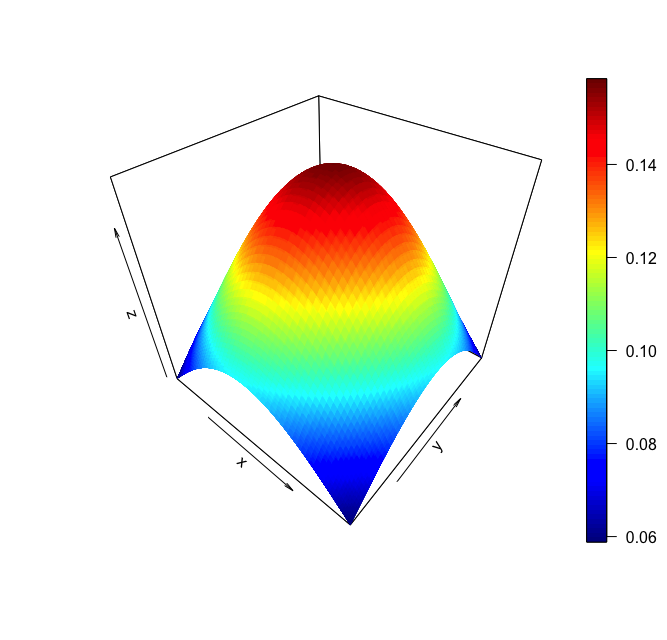
Figure 1. - Area Plot of 3-variable interaction.
What we’re doing is trying to understand the dynamics of the relationships between the factors involved in the process, and the outcome, just as we do every day, when we wake up late, until we figure out the best time to get up, so we won’t be late. Normally, we rely on past experience to make our assessments. Now, say we wanted to detect whether a person had skin cancer or not. The factors above are mostly external, and a little hard to measure. Could we expect each individual to have an exact metered account on the amount of exposure to skin radition they have had? Probably not. However, regardless of what external factors an individual has been exposed to, their skin will, so to speak, bare witness them. And so in trying to identify cancer, we may instead refer to the state of the skin, as a reflection of the conditions to which the person has been exposed to, much like to we can tell certain things about the composition of stars and planets light years away by observing the manner in which light is reflected off them.
The problem is that, as humans, when we go beyonnd one or two influencers, it gets harder and harder for us to reason about the way the factors in a phenomenon affect each other, and the outcome. For instance, we can easily reason about the impact of two different variables, x and y, on an outcome variable y using a countour or 3D plot (see Figure 1). The plot would not only tells us how each variable relates to the outcome, but how they relate to one another as well. For simpler problems, we may even do it in hour heads, e.g. with our present driving speed, we can easily estimate our arrival time at a given destination.
Back to our morning decisions problem, the later we get up, and the longer we take to get ourselves ready, the more likely we are to arrive late. Now, throw in the daily traffic state, the weather, construction work schedules for roads, maintenance of metro lines and we start facing some limitations. Further more, adding more data points to the problem adds to the complexity of the task. While these limitations can cause little harm on some scales, they can lead to poor decisions, especially when gone unnoticed. Even in every day tasks.
For instance, suppose we’re running a pizza delivery service, and we wanna figure out what is it about our service that our customers like the most. Fast delivery speed? Tasty pizza toppings, with mixed flavours? On the surface, both factors seem waranted, and fine. Who woudln’t want delicious pizza, promptly delivered to their house? But delivering pizza fast requires a good amount of logistical planning, as does having the necessary toppings avaiable. So then, we need to start asking ourselves, how fast do we need to be for customers, or laterally, what radious could we service our customers within 25min, assuming that’s how fast we should be? How much topping is good enough? Unlike logical processes, where the answer is an absolute true or false, processes and questions such as the ones we pose on the pizza serivce are stochastic in nature. We can’t say yes, or no for sure. However, given enough measurements, and a confident enough analysis, we may say yes or no, to a certain degree of belief.
It turns out that computers are fairly good at doing this with high dimensional data. Specifically, machine learning algorithms are good at doing this. What classification models, such as logistic regression and feedforward neural networks have in common is that they try to express, in a mathematical way, the manner in which the factors of phenomenon interact with each other to influence an outcome. For the skin cancer problem, we could have as features of our observations the size of particular cells, their level of activity, growth rate, and so on; The same could be done with the delivery by asking, for instance, given our delivery times, which customers rates us high and which ones rate us low? Beyond that, though, having a well trained model would allow us to feed it the information that we have about an order or a customer, and ask it whether it’s more likely they’ll rate our service one way or another. Since we are, in a manner of speech, hopeless at doing this mentally, then our only viable option is to defer the computation to the algorithms, and be mindful when interpreting their answers.
Finally, while we can avoid a morning rush by going to bed on time, I think it would be interesting to actually measure how much late you’re going to be with each minute of delay in your sleep, or just have a system with which you could debate how your day will go as you suggest different hours for getting up, the night before. Not that would I would like to know, but I’d find it interesting nonetheless. One thing is certain. I probably shouldn’t be writing this at 2am.