In this mini-series of posts, I will describe a hyper-parameter tuning experiment on the fashion-mnist dataset.
Hyper-paramater tuning is a very important aspect of training models in machine learning. Particularly with neural networks, where the architecture, optimizer and data can be subject to different parameters. When developing machine learning solutions, there is an interative cycle that can be adopted to enable fast iteration, continous targeted improvements, and testing of the solution - as with any other software systems problems. However, in practice, those iterations can cease as soon as there is a workable solution is in place. And more often than not, that workable solution runs on an initial guess of the right paramters. Thus, little to no hyper-paramter tuning takes place.
Thinking about breaking out of that trap, I wondered what kind of tools were out there for hyper-parameter tuning. I was interested in utilities that could perform several experiments to identify the right combination of parameters in an automated, and easy fashion.
For the problem itself, I chose to use the fashion-mnist dataset. This is because I wanted to see a relatively big difference between my hyper-parameter choices, and MNIST can be a bit too easy of a dataset to solve classification for. As an image dataset, fashion-mnist would be suitable to work with convolutional neural networks - which I personally hadn’t worked with in a while. Along the way, there were great many new things that I learned and re-learned about model training, particularly with convolutional neural networks, hyper-paramater tuning, and image data. To describe that experience, I wrote this mini-series of posts, and this is the first part.
Among from the many decisions one makes in the process of designing a learning solution, there are engineering decisions among them. Along this mini-series, I highlight some of the components design decisions in terms of what they do and don’t enable me to do.
The Data
Before we dive into the process, we should understand the data we’re working with. The fashion-mnist website and github page have links to source code with examples on how to visualize, and process the dataset.
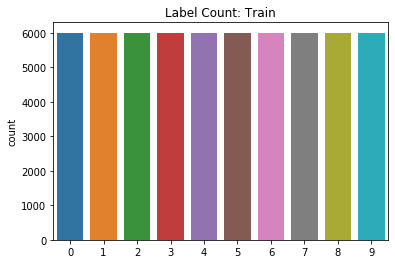
I used a notebook to observe specific samples of the data, to better understand the types of objects in them. There are 10 classes in total, ranging from sneakers to shirts, with some objects being more obvious than others.

There are 60,000 examples in the training set and 10,000 examples on the test set. It’s a very balanced problem.
Data Processing:
I wanted to train different models on the fashion-mnist dataset, including a standard fully connected nework, a convolutional network, and to apply some transfer learning. For convolutional models, depth can be a very important factor in model performance - both positively and negatively. Depending on the network configuration, inputs to convolutional networks can reduce in size after each layer or block of layers. For instance, pooling layers can drastically reduce the size of their input. Thus, in order to train high-depth networks, one needs an image that can be scaled down several times.
The fashion-mnist dataset has images of size 28x28. This was done intentionally, so that the dataset could be used as a drop-in replacement for MNIST. To avoid a hard limit of the network depth, I resized the images to 128x128. This is standard procedure. What was intriguing though is the method to do this.
Image Sizing Fidelity
There are various options out there for resizing images. To me, a good data pipeline is not only tested, but visually inspected. Inputs to models are very important, and it can be easy to make trivial mistakes during processing, e.g. shifting pixels, or missing values.
As such, I wanted to visually inspect the different options to see what they would render. After all, if the input is made drastically noisy, it can actually hurt model performance.
To that end, I explored two methods: the keras image utility and OpenCV. For both, I tried to resize the same set of images.
Keras Image Util
Keras has a standard set of tools for image processing, including enhancement. I tried using its image resizing methods to see what it would render.
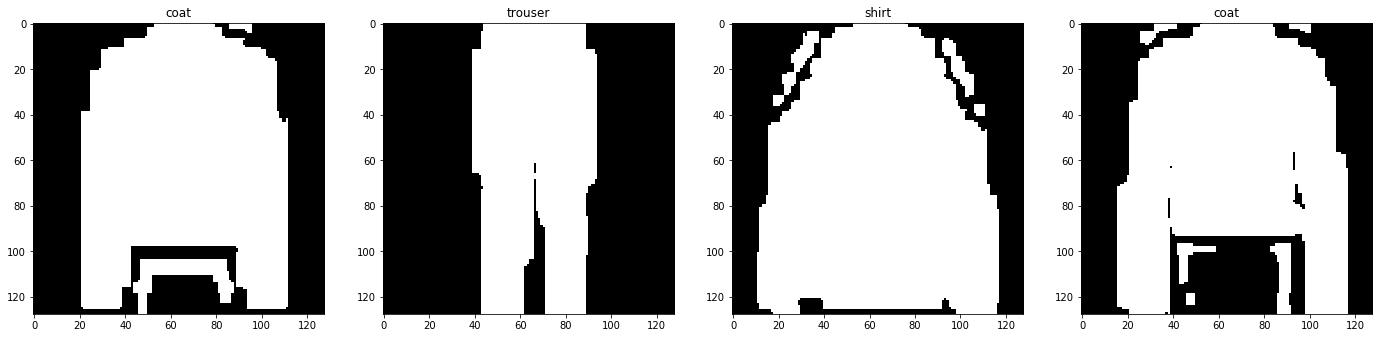
Unfortunately, the results looked distorted.
OpenCV
OpenCV is an image processing toolkit. It also has provides image resizing functionality, so I tested it out.

The results with OpenCV appear to be more stable and reliable, i.e. of higher fidelity. Though I admit I did not actually run training with both options and compare them.
Dataflow
When creating the pipeline to transform data, I had my first model in mind. I wanted a fully connected neural network to serve as a baseline. As such, it would take the image as a 1-D vector and train on that. The only transformation required would be scaling of values from the [0-255] range that is RGB to the range of [0-1].
As such, I wrote a module to up-size the images and scale them. That way, training would have one less step, which when training tens of models can save up some computational time on aggregate - as would happen in set of hyper-parameter tuning experiments.
Once I had the baseline, I started working on a convolutional model. I considered what adding image enhancements would look like. The basic trade-off here is compute vs storage. You can pre-process all images at once, creating different croppings, rotations, color schemes. Naturally, the drawback of doing this is that the data size adds up with each operation. The benefit, on the other hand, is that training has less steps. I went with this approach first, and it worked nicely. Storage wasn’t a big issue - after all, fashion-mnist is not that large of a dataset - it takes up ~200MB in it’s base form.
Once it was time to experiment with transfer learning, there was another decision to be made: when to extract the embeddings? As before, I could run inference on the images offline with the pre-trained model, and save the embeddings as the training data. The image enhancements would then be performed prior to running inference on the pre-trained model. This would generate a different dataset with more images.
For reference, the sized up images saved as numpy arrays take up ~3GB. If you apply T transformers, that leaves you with 3xT GB of data.
I wanted to (1) unify the pre-processing workflow, (2) and reduce to the amount of data produced (3) provide flexibility on how to use the data for the different model experiments. For example, I can compare using cropping and not using it more easily if a network that uses it performs cropping at run-time. I experimented with delaying all enhancement and transfer steps to runtime. But I had to mitigate the data blow up during training - both in terms of processing and memory. I landed on the following:
- The pre-processing pipeline would only resize the images and scale them
- During training, networks could have layers stacked on at the head to pre-process data (e.g. crop images)
- This enhancement can be probabilistic, i.e. not all transformations need to be applied to every image. Since training runs for several epochs, most images will end up going through at least one transformation, thus ensuring exposure to the model with keeping data blow up to a minimum
- Embedding extraction would also be defined as part of the network, by being layered at the head. This way, a network can be exported with the frozen pre-trained graph, which enables the consumer of an exported model to just load it and run inference directly without having to pre-process the data themselves.
This, naturally, simplified the offline pre-processing logic. To enable the online transformations, I implemented custom layers using the keras layers API.
In the end, the generated three datasets: training and validation, by splitting the training set into two; and a test set that comes with the download.
In the next post, I’ll address creating a baseline model for this problem, and experimenting with guided hyper-paramater tuning.